
【转载】06.ClickHouse表引擎之外部集成表引擎
[TOC]前言本篇文章转载于大佬文章:大数据技术与数仓一、概述ClickHouse提供了许多与外部系统集成的方法,包括一些表引擎。这些表引擎与其他类型的表引擎类似,可以用于将外部数据导入到ClickHouse中,或者在ClickHouse中直接操作外部数据源。例如直接读取HDFS的文件或者MySQL数据库的表。这些表引擎只负责元数据管理和数据查询,而它们自身通常并不负责数据的写入,数据文件直接由外部系统提供。目前ClickHouse提供了下面的外部集成表引擎:ODBC:通过指定odbc连接读取数据源JDBC:通过指定jdbc连接读取数据源;MySQL:将MySQL作为数据存储,直接查询其...
【转载】05.ClickHouse表引擎之MergeTree系列引擎
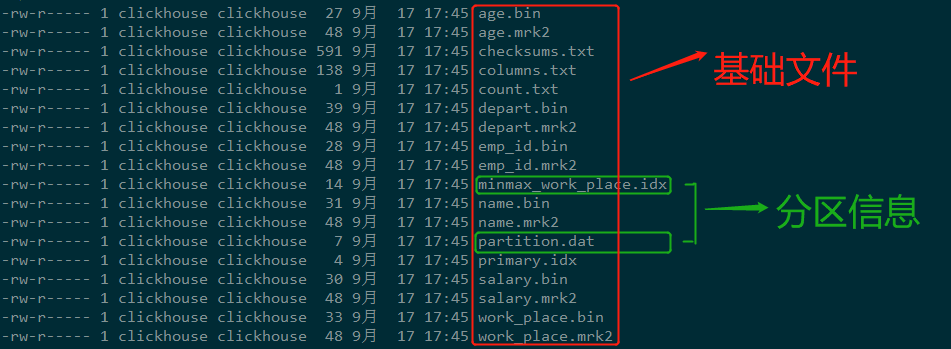
[TOC]前言本篇文章转载于大佬文章:大数据技术与数仓一、概述在所有的表引擎中,最为核心的当属MergeTree系列表引擎,这些表引擎拥有最为强大的性能和最广泛的使用场合。对于非MergeTree系列的其他引擎而言,主要用于特殊用途,场景相对有限。而MergeTree系列表引擎是官方主推的存储引擎,支持几乎所有ClickHouse核心功能。二、MergeTree表引擎MergeTree在写入一批数据时,数据总会以数据片段的形式写入磁盘,且数据片段不可修改。为了避免片段过多,ClickHouse会通过后台线程,定期合并这些数据片段,属于相同分区的数据片段会被合成一个新的片段。这种数据片段往...
【转载】04.ClickHouse表引擎之Log系列表引擎
[TOC]前言本篇文章转载于大佬文章:大数据技术与数仓一、概述本文将介绍ClickHouse中一个非常重要的概念—表引擎(table engine)。如果对MySQL熟悉的话,或许你应该听说过InnoDB和MyISAM存储引擎。不同的存储引擎提供不同的存储机制、索引方式、锁定水平等功能,也可以称之为表类型。ClickHouse提供了丰富的表引擎,这些不同的表引擎也代表着不同的表类型。比如数据表拥有何种特性、数据以何种形式被存储以及如何被加载。本文会对ClickHouse中常见的表引擎进行介绍,主要包括以下内容:表引擎的作用是什么MergeTree系列引擎Log家族系列引擎外部集成表引擎其...
【转载】03.ClickHouse数据类型
[TOC]前言ClickHouse的数据类型分为:基础类型复合类型特殊类型一、基础类型1.1 数值类型ClickHouse的数值类型和Numpy的数值类型类似,比如int32、int64、uint32、float32 和float64等。整数ClickHouse支持有符号和无符号的整数。有符号整数Int<位数>:名称范围大概范围对应MySQL数据类型Int8-128 ~ 127百TinyintInt16-32768 ~32767万SmallintInt32-2147483648 ~ 2147483647十亿IntInt64-9223372036854775808 ~ 9223...
02.ClickHouse单机版安装教程
[TOC]前言安装环境:CentOS 7.9安装版本:clickhouse 21.7.3.14-2版本选择:版本命名规则 Year.Major.Minor.patchYear.Major.1.patch 1 表示测试版,大于1表示稳定版本。有重大的更新和新特性主要在Minor为2的版本。体验最新的测试功能可以选择prestable或者testing版本。对于企业来说可以选择LTS的稳定版本,差不多6个月分布一个LTS版本,一年发布两个。维护的周期要比stable版本长。一、准备阶段(1)关闭防火墙# systemctl stop firewalld # systemctl disable...

01.ClickHouse介绍
[TOC]一、概述ClickHouse 是俄罗斯的 Yandex 于 2016 年开源的列式存储数据库(DBMS),使用 C++ 语言编写,主要用于在线分析处理查询(OLAP),能够使用SQL查询实时生成分析数据报告。二、ClickHouse的特点2.1 列式存储以下面的表为例:IDNameAge1张三182李四223王五34(1)采用行式存储时,数据在磁盘上的组织结构为: 好处是想查某个人所有的属性时,可以通过一次磁盘查找加顺序读取就可以。但是当想 查所有人的年龄时,需要不停的查找,或者全表扫描才行,遍历的很多数据都是不需要的。(2)采用列式存储时,数据在磁盘上的组织结...
什么是OLAP
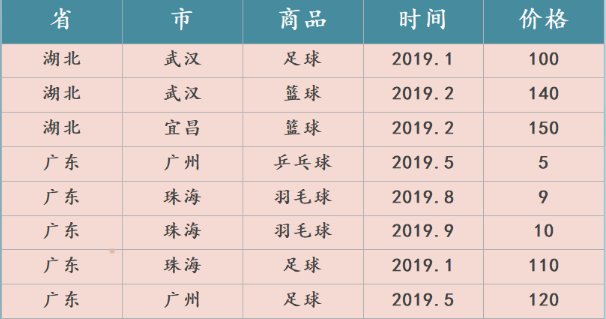
[TOC]一、介绍 OLAP 名为联机分析处理,又可以称之为多维分析处理,是由关系型数据之父于 1993 年提出的概念。顾名思义,它指的是通过多种不同的维度审视数据,进行深层次分析。维度可以看成是观察数据的一种视角,例如人类能看到的世界是三维的,它包含长、宽、高三个维度。直接一点理解,维度就好比是一张数据表的字段,而多维分析则是基于这些字段进行聚合查询。那么多维分析通常都包含哪些基本操作呢?为了更好地理解多维分析的概念,可以通过对一个立方体的图像进行具象化来描述。示例以如下一张销售明细表为例:那么数据立方体可以进行如下操作:下钻:从高层次向低层次明细数据进行穿透。例如从 ...
07.Azkaban条件工作流介绍
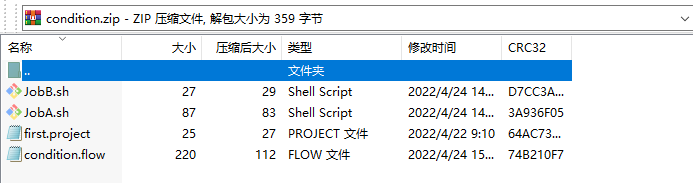
[TOC]一、概述 条件工作流功能允许用户自定义执行条件来决定是否运行某些Job。条件可以由当前Job的父 Job 输出的运行时参数构成,也可以使用预定义宏。在这些条件下,用户可以在确定 Job执行逻辑时获得更大的灵活性,例如,只要父 Job 之一成功,就可以运行当前 Job。二、运行时参数案例2.1 基本原理(1)父 Job 将参数写入JOB_OUTPUT_PROP_FILE环境变量所指向的文件;(2)子 Job 使用 ${jobName:param}来获取父 Job 输出的参数并定义执行条件2.2 支持的条件运算符符号说明==等于!=不等于>大于>=大于等...
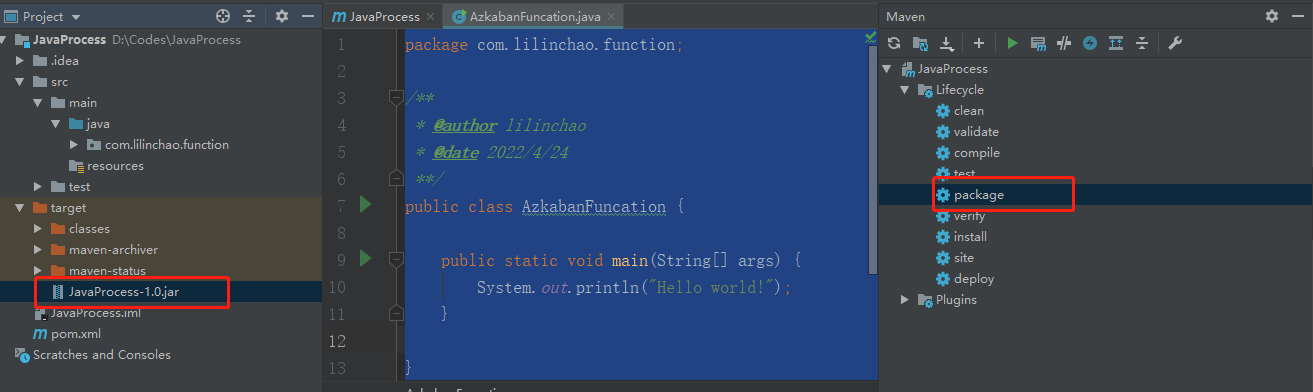
06.Azkaban之JavaProcess任务类型
[TOC]前言本篇将以一个简单的案例演示通过Azkaban平台来调度执行Java程序。一、Azkaban调度类型介绍azkaban 可以支持非常多的任务类型,常用的任务类型有如下几种:Command:使用Linux shell命令行任务。HadoopShell:这和Command一样也是命令类型,只不过可以和Hadoop集群通信。Java:调度执行Java任务。hadoopJava:也是一种Java类型,可以和hadoop集群通信,可以通过运行hadoopJava作业来创建大多数Hadoop作业类型,例如Pig,Hive等。Pig:pig脚本任务。Hive:支持 执行hiveSQL 任务...

05.Azkaban失败重试配置与使用
[TOC]一、简介Azkaban失败重试分为两种:自动失败重试和手动失败重试。作用自动失败重试:当任务第一次执行失败后,可以根据特定时间间隔来进行自动重新执行。手动失败重试:当任务经历过自动失败重试,在某个节点依旧执行失败,排查修复完问题,继续执行任务时,可以跳过执行成功的工作单元,从上次失败的工作单元向下执行。场景自动失败重试由于暂时网络波动导致的超时、暂时资源不足导致的超时等原因产生的暂时性故障导致的任务失败。手动失败重试由于服务器宕机、任务配置出错等原因无法通过自动失败重试解决的问题,当问题修复完之后,需要手动失败重试继续执行任务。二、自动失败重试案例需求:如果执行任务失败,需要重...