李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
【转载】05.ClickHouse表引擎之MergeTree系列引擎
Leefs
2022-04-29 AM
1354℃
0条
[TOC] ### 前言 本篇文章转载于大佬文章:[大数据技术与数仓](https://www.modb.pro/db/79081) ### 一、概述 在所有的表引擎中,最为核心的当属MergeTree系列表引擎,这些表引擎拥有最为强大的性能和最广泛的使用场合。对于非MergeTree系列的其他引擎而言,主要用于特殊用途,场景相对有限。而MergeTree系列表引擎是官方主推的存储引擎,支持几乎所有ClickHouse核心功能。 ### 二、MergeTree表引擎 MergeTree在写入一批数据时,数据总会以数据片段的形式写入磁盘,且数据片段不可修改。 为了避免片段过多,ClickHouse会通过后台线程,定期合并这些数据片段,属于相同分区的数据片段会被合成一个新的片段。 这种数据片段往复合并的特点,也正是合并树名称的由来。 **MergeTree作为家族系列最基础的表引擎,主要有以下特点:** + 存储的数据按照主键排序:允许创建稀疏索引,从而加快数据查询速度 + 支持分区,可以通过PRIMARY KEY语句指定分区字段。 + 支持数据副本 + 支持数据采样 #### 建表语法 ```sql CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster] ( name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1], name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2], ... INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1, INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2 ) ENGINE = MergeTree() ORDER BY expr [PARTITION BY expr] [PRIMARY KEY expr] [SAMPLE BY expr] [TTL expr [DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'], ...] [SETTINGS name=value, ...] ``` + **ENGINE**:ENGINE = MergeTree(),MergeTree引擎没有参数 + **ORDER BY**:排序字段。比如ORDER BY (Col1, Col2),值得注意的是,如果没有指定主键,默认情况下 sorting key(排序字段)即为主键。如果不需要排序,则可以使用**ORDER BY tuple()**语法,这样的话,创建的表也就不包含主键。这种情况下,ClickHouse会按照插入的顺序存储数据。**必选**。 + **PARTITION BY**:分区字段,**可选**。 + **PRIMARY KEY**:指定主键,如果排序字段与主键不一致,可以单独指定主键字段。否则默认主键是排序字段。**可选**。 + **SAMPLE BY**:采样字段,如果指定了该字段,那么主键中也必须包含该字段。比如`SAMPLE BY intHash32(UserID) ORDER BY (CounterID, EventDate, intHash32(UserID))`。**可选**。 + **TTL**:数据的存活时间。在MergeTree中,可以为某个列字段或整张表设置TTL。当时间到达时,如果是列字段级别的TTL,则会删除这一列的数据;如果是表级别的TTL,则会删除整张表的数据。**可选**。 + **SETTINGS**:额外的参数配置。**可选**。 #### 建表示例 ```sql CREATE TABLE emp_mergetree ( emp_id UInt16 COMMENT '员工id', name String COMMENT '员工姓名', work_place String COMMENT '工作地点', age UInt8 COMMENT '员工年龄', depart String COMMENT '部门', salary Decimal32(2) COMMENT '工资' )ENGINE=MergeTree() ORDER BY emp_id PARTITION BY work_place ; -- 插入数据 INSERT INTO emp_mergetree VALUES (1,'tom','上海',25,'技术部',20000),(2,'jack','上海',26,'人事部',10000); INSERT INTO emp_mergetree VALUES (3,'bob','北京',33,'财务部',50000),(4,'tony','杭州',28,'销售事部',50000); -- 查询数据 -- 按work_place进行分区 cdh04 :) select * from emp_mergetree; SELECT * FROM emp_mergetree ┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐ │ 3 │ bob │ 北京 │ 33 │ 财务部 │ 50000.00 │ └────────┴──────┴────────────┴─────┴────────┴──────────┘ ┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐ │ 1 │ tom │ 上海 │ 25 │ 技术部 │ 20000.00 │ │ 2 │ jack │ 上海 │ 26 │ 人事部 │ 10000.00 │ └────────┴──────┴────────────┴─────┴────────┴──────────┘ ┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart───┬───salary─┐ │ 4 │ tony │ 杭州 │ 28 │ 销售事部 │ 50000.00 │ └────────┴──────┴────────────┴─────┴──────────┴──────────┘ ``` 查看一下数据存储格式,可以看出,存在三个分区文件夹,每一个分区文件夹内存储了对应分区的数据。 ```bash [root@cdh04 emp_mergetree]# pwd /var/lib/clickhouse/data/default/emp_mergetree [root@cdh04 emp_mergetree]# ll 总用量 16 drwxr-x--- 2 clickhouse clickhouse 4096 9月 17 17:45 1c89a3ba9fe5fd53379716a776c5ac34_3_3_0 drwxr-x--- 2 clickhouse clickhouse 4096 9月 17 17:44 40d45822dbd7fa81583d715338929da9_1_1_0 drwxr-x--- 2 clickhouse clickhouse 4096 9月 17 17:45 a6155dcc1997eda1a348cd98b17a93e9_2_2_0 drwxr-x--- 2 clickhouse clickhouse 6 9月 17 17:43 detached -rw-r----- 1 clickhouse clickhouse 1 9月 17 17:43 format_version.txt ``` 进入一个分区目录查看 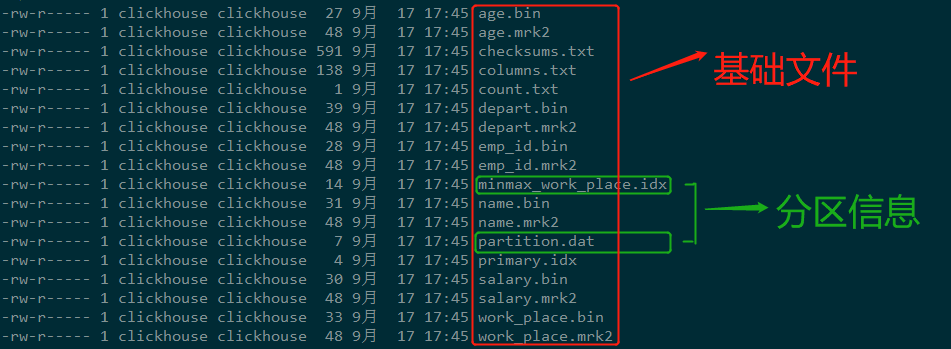 + **checksums.txt**:校验文件,使用二进制格式存储。它保存了余下各类文件(primary. idx、count.txt等)的size大小及size的哈希值,用于快速校验文件的完整性和正确性。 + **columns.txt**:列信息文件,使用明文格式存储。用于保存此数据分区下的列字段信息,例如 ```bash [root@cdh04 1c89a3ba9fe5fd53379716a776c5ac34_3_3_0]# cat columns.txt columns format version: 1 6 columns: `emp_id` UInt16 `name` String `work_place` String `age` UInt8 `depart` String `salary` Decimal(9, 2) ``` + **count.txt**:计数文件,使用明文格式存储。用于记录当前数据分区目录下数据的总行数 + **primary.idx**:一级索引文件,使用二进制格式存储。用于存放稀疏索引,一张MergeTree表只能声明一次一级索引,**即通过ORDER BY或者PRIMARY KEY**指定字段。借助稀疏索引,在数据查询的时能够排除主键条件范围之外的数据文件,从而有效减少数据扫描范围,加速查询速度。 + **列.bin**:数据文件,使用压缩格式存储,默认为LZ4压缩格式,用于存储某一列的数据。由于MergeTree采用列式存储,所以每一个列字段都拥有独立的`.bin`数据文件,并以列字段名称命名。 + **列.mrk2**:列字段标记文件,使用二进制格式存储。标记文件中保存了`.bin`文件中数据的偏移量信息。 + **partition.dat与minmax_[Column].idx**:如果指定了分区键,则会额外生成partition.dat与minmax索引文件,它们均使用二进制格式存储。**partition.dat**用于保存当前分区下分区表达式最终生成的值,即分区字段值;而**minmax**索引用于记录当前分区下分区字段对应原始数据的最小和最大值。比如当使用EventTime字段对应的原始数据为2020-09-17、2020-09-30,分区表达式为PARTITION BY toYYYYMM(EventTime),即按月分区。partition.dat中保存的值将会是2019-09,而minmax索引中保存的值将会是2020-09-17 2020-09-30。 **注意点** + 多次插入数据,会生成多个分区文件 ```sql -- 新插入两条数据 cdh04 :) INSERT INTO emp_mergetree VALUES (5,'robin','北京',35,'财务部',50000),(6,'lilei','北京',38,'销售事部',50000); -- 查询结果 cdh04 :) select * from emp_mergetree; ┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐ │ 3 │ bob │ 北京 │ 33 │ 财务部 │ 50000.00 │ └────────┴──────┴────────────┴─────┴────────┴──────────┘ ┌─emp_id─┬─name──┬─work_place─┬─age─┬─depart───┬───salary─┐ │ 5 │ robin │ 北京 │ 35 │ 财务部 │ 50000.00 │ │ 6 │ lilei │ 北京 │ 38 │ 销售事部 │ 50000.00 │ └────────┴───────┴────────────┴─────┴──────────┴──────────┘ ┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐ │ 1 │ tom │ 上海 │ 25 │ 技术部 │ 20000.00 │ │ 2 │ jack │ 上海 │ 26 │ 人事部 │ 10000.00 │ └────────┴──────┴────────────┴─────┴────────┴──────────┘ ┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart───┬───salary─┐ │ 4 │ tony │ 杭州 │ 28 │ 销售事部 │ 50000.00 │ └────────┴──────┴────────────┴─────┴──────────┴──────────┘ ``` 可以看出,新插入的数据新生成了一个数据块,并没有与原来的分区数据在一起,我们可以执行**optimize**命令,执行合并操作 ```sql -- 执行合并操作 cdh04 :) OPTIMIZE TABLE emp_mergetree PARTITION '北京'; -- 再次执行查询 cdh04 :) select * from emp_mergetree; SELECT * FROM emp_mergetree ┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐ │ 1 │ tom │ 上海 │ 25 │ 技术部 │ 20000.00 │ │ 2 │ jack │ 上海 │ 26 │ 人事部 │ 10000.00 │ └────────┴──────┴────────────┴─────┴────────┴──────────┘ ┌─emp_id─┬─name──┬─work_place─┬─age─┬─depart───┬───salary─┐ │ 3 │ bob │ 北京 │ 33 │ 财务部 │ 50000.00 │ │ 5 │ robin │ 北京 │ 35 │ 财务部 │ 50000.00 │ │ 6 │ lilei │ 北京 │ 38 │ 销售事部 │ 50000.00 │ └────────┴───────┴────────────┴─────┴──────────┴──────────┘ ┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart───┬───salary─┐ │ 4 │ tony │ 杭州 │ 28 │ 销售事部 │ 50000.00 │ └────────┴──────┴────────────┴─────┴──────────┴──────────┘ ``` 执行上面的合并操作之后,会新生成一个该分区的文件夹,原来的分区文件夹不变。 - 在MergeTree中主键并不用于去重,而是用于索引,加快查询速度 ```sql -- 插入一条相同主键的数据 INSERT INTO emp_mergetree VALUES (1,'sam','杭州',35,'财务部',50000); -- 会发现该条数据可以插入,由此可知,并不会对主键进行去重 ``` ### 三、ReplacingMergeTree表引擎 上文提到**MergeTree**表引擎无法对相同主键的数据进行去重,ClickHouse提供了ReplacingMergeTree引擎,可以针对相同主键的数据进行去重,它能够在合并分区时删除重复的数据。值得注意的是,**ReplacingMergeTree**只是在一定程度上解决了数据重复问题,但是并不能完全保障数据不重复。 #### 建表语法 ```sql CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster] ( name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1], name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2], ... ) ENGINE = ReplacingMergeTree([ver]) [PARTITION BY expr] [ORDER BY expr] [PRIMARY KEY expr] [SAMPLE BY expr] [SETTINGS name=value, ...] ``` - [ver]:可选参数,列的版本,可以是UInt、Date或者DateTime类型的字段作为版本号。该参数决定了数据去重的方式。 - 当没有指定[ver]参数时,保留最新的数据;如果指定了具体的值,保留最大的版本数据。 #### 建表示例 ```sql CREATE TABLE emp_replacingmergetree ( emp_id UInt16 COMMENT '员工id', name String COMMENT '员工姓名', work_place String COMMENT '工作地点', age UInt8 COMMENT '员工年龄', depart String COMMENT '部门', salary Decimal32(2) COMMENT '工资' )ENGINE=ReplacingMergeTree() ORDER BY emp_id PRIMARY KEY emp_id PARTITION BY work_place ; -- 插入数据 INSERT INTO emp_replacingmergetree VALUES (1,'tom','上海',25,'技术部',20000),(2,'jack','上海',26,'人事部',10000); INSERT INTO emp_replacingmergetree VALUES (3,'bob','北京',33,'财务部',50000),(4,'tony','杭州',28,'销售事部',50000); ``` #### 注意点 当我们再次向该表插入具有相同主键的数据时,观察查询数据的变化 ```sql INSERT INTO emp_replacingmergetree VALUES (1,'tom','上海',25,'技术部',50000); -- 查询数据,由于没有进行合并,所以存在主键重复的数据 cdh04 :) select * from emp_replacingmergetree; SELECT * FROM emp_replacingmergetree ┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐ │ 1 │ tom │ 上海 │ 25 │ 技术部 │ 20000.00 │ │ 2 │ jack │ 上海 │ 26 │ 人事部 │ 10000.00 │ └────────┴──────┴────────────┴─────┴────────┴──────────┘ ┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐ │ 3 │ bob │ 北京 │ 33 │ 财务部 │ 50000.00 │ └────────┴──────┴────────────┴─────┴────────┴──────────┘ ┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart───┬───salary─┐ │ 4 │ tony │ 杭州 │ 28 │ 销售事部 │ 50000.00 │ └────────┴──────┴────────────┴─────┴──────────┴──────────┘ ┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐ │ 1 │ tom │ 上海 │ 25 │ 技术部 │ 50000.00 │ └────────┴──────┴────────────┴─────┴────────┴──────────┘ -- 执行合并操作 optimize table emp_replacingmergetree final; -- 再次查询,相同主键的数据,保留最近插入的数据,旧的数据被清除 cdh04 :) select * from emp_replacingmergetree; SELECT * FROM emp_replacingmergetree ┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐ │ 1 │ tom │ 上海 │ 25 │ 技术部 │ 50000.00 │ │ 2 │ jack │ 上海 │ 26 │ 人事部 │ 10000.00 │ └────────┴──────┴────────────┴─────┴────────┴──────────┘ ┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart───┬───salary─┐ │ 4 │ tony │ 杭州 │ 28 │ 销售事部 │ 50000.00 │ └────────┴──────┴────────────┴─────┴──────────┴──────────┘ ┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐ │ 3 │ bob │ 北京 │ 33 │ 财务部 │ 50000.00 │ └────────┴──────┴────────────┴─────┴────────┴──────────┘ ``` 从上面的示例中可以看出,ReplacingMergeTree是支持对数据去重的,那么是根据什么进行去重呢?答案是:**ReplacingMergeTree在去除重复数据时,是以ORDERBY排序键为基准的,而不是PRIMARY KEY**。 我们在看一个示例: ```sql CREATE TABLE emp_replacingmergetree1 ( emp_id UInt16 COMMENT '员工id', name String COMMENT '员工姓名', work_place String COMMENT '工作地点', age UInt8 COMMENT '员工年龄', depart String COMMENT '部门', salary Decimal32(2) COMMENT '工资' )ENGINE=ReplacingMergeTree() ORDER BY (emp_id,name) -- 注意排序key是两个字段 PRIMARY KEY emp_id -- 主键是一个字段 PARTITION BY work_place ; -- 插入数据 INSERT INTO emp_replacingmergetree1 VALUES (1,'tom','上海',25,'技术部',20000),(2,'jack','上海',26,'人事部',10000); INSERT INTO emp_replacingmergetree1 VALUES (3,'bob','北京',33,'财务部',50000),(4,'tony','杭州',28,'销售事部',50000); ``` 再次向该表中插入相同emp_id和name的数据,并执行合并操作,再观察数据 ```sql -- 插入数据 INSERT INTO emp_replacingmergetree1 VALUES (1,'tom','上海',25,'技术部',50000),(1,'sam','上海',25,'技术部',20000); -- 执行合并操作 optimize table emp_replacingmergetree1 final; -- 再次查询,可见相同的emp_id和name数据被去重,而相同的主键emp_id不会去重 -- ReplacingMergeTree在去除重复数据时,是以ORDERBY排序键为基准的,而不是PRIMARY KEY cdh04 :) select * from emp_replacingmergetree1; SELECT * FROM emp_replacingmergetree1 ┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐ │ 3 │ bob │ 北京 │ 33 │ 财务部 │ 50000.00 │ └────────┴──────┴────────────┴─────┴────────┴──────────┘ ┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐ │ 1 │ sam │ 上海 │ 25 │ 技术部 │ 20000.00 │ │ 1 │ tom │ 上海 │ 25 │ 技术部 │ 50000.00 │ │ 2 │ jack │ 上海 │ 26 │ 人事部 │ 10000.00 │ └────────┴──────┴────────────┴─────┴────────┴──────────┘ ┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart───┬───salary─┐ │ 4 │ tony │ 杭州 │ 28 │ 销售事部 │ 50000.00 │ └────────┴──────┴────────────┴─────┴──────────┴──────────┘ ``` 至此,我们知道了ReplacingMergeTree是支持去重的,并且是按照**ORDERBY排序键**为基准进行去重的。 细心的你会发现,上面的重复数据是在一个分区内的,那么如果重复的数据不在一个分区内,会发生什么现象呢?我们再次向上面的**emp_replacingmergetree1**表插入不同分区的重复数据 ```sql -- 插入数据 INSERT INTO emp_replacingmergetree1 VALUES (1,'tom','北京',26,'技术部',10000); -- 执行合并操作 optimize table emp_replacingmergetree1 final; -- 再次查询 -- 发现 1 │ tom │ 北京 │ 26 │ 技术部 │ 10000.00 -- 与 1 │ tom │ 上海 │ 25 │ 技术部 │ 50000.00 -- 数据重复,因为这两行数据不在同一个分区内 -- 这是因为ReplacingMergeTree是以分区为单位删除重复数据的。 -- 只有在相同的数据分区内重复的数据才可以被删除,而不同数据分区之间的重复数据依然不能被剔除 cdh04 :) select * from emp_replacingmergetree1; SELECT * FROM emp_replacingmergetree1 ┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐ │ 1 │ tom │ 北京 │ 26 │ 技术部 │ 10000.00 │ │ 3 │ bob │ 北京 │ 33 │ 财务部 │ 50000.00 │ └────────┴──────┴────────────┴─────┴────────┴──────────┘ ┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐ │ 1 │ sam │ 上海 │ 25 │ 技术部 │ 20000.00 │ │ 1 │ tom │ 上海 │ 25 │ 技术部 │ 50000.00 │ │ 2 │ jack │ 上海 │ 26 │ 人事部 │ 10000.00 │ └────────┴──────┴────────────┴─────┴────────┴──────────┘ ┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart───┬───salary─┐ │ 4 │ tony │ 杭州 │ 28 │ 销售事部 │ 50000.00 │ └────────┴──────┴────────────┴─────┴──────────┴──────────┘ ``` #### 总结 - **如何判断数据重复** ReplacingMergeTree在去除重复数据时,是以ORDERBY排序键为基准的,而不是PRIMARY KEY。 - **何时删除重复数据** 在执行分区合并时,会触发删除重复数据。optimize的合并操作是在后台执行的,无法预测具体执行时间点,除非是手动执行。 - **不同分区的重复数据不会被去重** ReplacingMergeTree是以分区为单位删除重复数据的。只有在相同的数据分区内重复的数据才可以被删除,而不同数据分区之间的重复数据依然不能被剔除。 - **数据去重的策略是什么** 如果没有设置**[ver]版本号**,则保留同一组重复数据中的最新插入的数据;如果设置了**[ver]版本号**,则保留同一组重复数据中**ver字段取值最大的那一行**。 - **optimize命令使用** 一般在数据量比较大的情况,尽量不要使用该命令。因为在海量数据场景下,执行optimize要消耗大量时间 ### 四、SummingMergeTree表引擎 #### 概述 该引擎继承了MergeTree引擎,当合并 `SummingMergeTree`表的数据片段时,ClickHouse 会把所有具有相同主键的行合并为一行,该行包含了被合并的行中具有数值数据类型的列的汇总值,即如果存在重复的数据,会对对这些重复的数据进行合并成一条数据,类似于group by的效果。 推荐将该引擎和 `MergeTree`一起使用。例如,将完整的数据存储在 `MergeTree`表中,并且使用 `SummingMergeTree`来存储聚合数据。这种方法可以避免因为使用不正确的主键组合方式而丢失数据。 如果用户只需要查询数据的汇总结果,不关心明细数据,并且数据的汇总条件是预先明确的,即**GROUP BY的分组字段是确定的**,可以使用该表引擎。 #### 建表语法 ```sql CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster] ( name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1], name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2], ... ) ENGINE = SummingMergeTree([columns]) -- 指定合并汇总字段 [PARTITION BY expr] [ORDER BY expr] [SAMPLE BY expr] [SETTINGS name=value, ...] ``` #### 建表示例 ```sql CREATE TABLE emp_summingmergetree ( emp_id UInt16 COMMENT '员工id', name String COMMENT '员工姓名', work_place String COMMENT '工作地点', age UInt8 COMMENT '员工年龄', depart String COMMENT '部门', salary Decimal32(2) COMMENT '工资' )ENGINE=SummingMergeTree(salary) ORDER BY (emp_id,name) -- 注意排序key是两个字段 PRIMARY KEY emp_id -- 主键是一个字段 PARTITION BY work_place ; -- 插入数据 INSERT INTO emp_summingmergetree VALUES (1,'tom','上海',25,'技术部',20000),(2,'jack','上海',26,'人事部',10000); INSERT INTO emp_summingmergetree VALUES (3,'bob','北京',33,'财务部',50000),(4,'tony','杭州',28,'销售事部',50000); ``` 当我们再次插入具有相同emp_id,name的数据时,观察结果 ```sql INSERT INTO emp_summingmergetree VALUES (1,'tom','上海',25,'信息部',10000),(1,'tom','北京',26,'人事部',10000); cdh04 :) select * from emp_summingmergetree; -- 查询 SELECT * FROM emp_summingmergetree ┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐ │ 3 │ bob │ 北京 │ 33 │ 财务部 │ 50000.00 │ └────────┴──────┴────────────┴─────┴────────┴──────────┘ ┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐ │ 1 │ tom │ 上海 │ 25 │ 技术部 │ 20000.00 │ │ 2 │ jack │ 上海 │ 26 │ 人事部 │ 10000.00 │ └────────┴──────┴────────────┴─────┴────────┴──────────┘ ┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart───┬───salary─┐ │ 4 │ tony │ 杭州 │ 28 │ 销售事部 │ 50000.00 │ └────────┴──────┴────────────┴─────┴──────────┴──────────┘ ┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐ │ 1 │ tom │ 北京 │ 26 │ 人事部 │ 10000.00 │ └────────┴──────┴────────────┴─────┴────────┴──────────┘ ┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐ │ 1 │ tom │ 上海 │ 25 │ 信息部 │ 10000.00 │ └────────┴──────┴────────────┴─────┴────────┴──────────┘ -- 执行合并操作 optimize table emp_summingmergetree final; cdh04 :) select * from emp_summingmergetree; -- 再次查询,新插入的数据 1 │ tom │ 上海 │ 25 │ 信息部 │ 10000.00 -- 原来的数据 : 1 │ tom │ 上海 │ 25 │ 技术部 │ 20000.00 -- 这两行数据合并成: 1 │ tom │ 上海 │ 25 │ 技术部 │ 30000.00 SELECT * FROM emp_summingmergetree ┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐ │ 1 │ tom │ 北京 │ 26 │ 人事部 │ 10000.00 │ │ 3 │ bob │ 北京 │ 33 │ 财务部 │ 50000.00 │ └────────┴──────┴────────────┴─────┴────────┴──────────┘ ┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐ │ 1 │ tom │ 上海 │ 25 │ 技术部 │ 30000.00 │ │ 2 │ jack │ 上海 │ 26 │ 人事部 │ 10000.00 │ └────────┴──────┴────────────┴─────┴────────┴──────────┘ ┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart───┬───salary─┐ │ 4 │ tony │ 杭州 │ 28 │ 销售事部 │ 50000.00 │ └────────┴──────┴────────────┴─────┴──────────┴──────────┘ ``` #### 注意点 要保证**PRIMARY KEY expr**指定的主键是**ORDER BY expr** 指定字段的前缀,比如 ```sql -- 允许 ORDER BY (A,B,C) PRIMARY KEY A -- 会报错 -- DB::Exception: Primary key must be a prefix of the sorting key ORDER BY (A,B,C) PRIMARY KEY B ``` 这种强制约束保障了即便在两者定义不同的情况下,主键仍然是排序键的前缀,不会出现索引与数据顺序混乱的问题。 #### 总结 - **SummingMergeTree是根据什么对两条数据进行合并的** 用ORBER BY排序键作为聚合数据的条件Key。即如果排序key是相同的,则会合并成一条数据,并对指定的合并字段进行聚合。 - **仅对分区内的相同排序key的数据行进行合并** 以数据分区为单位来聚合数据。当分区合并时,同一数据分区内聚合Key相同的数据会被合并汇总,而不同分区之间的数据则不会被汇总。 - **如果没有指定聚合字段,会怎么聚合** 如果没有指定聚合字段,则会按照非主键的数值类型字段进行聚合 - **对于非汇总字段的数据,该保留哪一条** 如果两行数据除了排序字段相同,其他的非聚合字段不相同,那么在聚合发生时,会保留最初的那条数据,新插入的数据对应的那个字段值会被舍弃 ```sql -- 新插入的数据: 1 │ tom │ 上海 │ 25 │ 信息部 │ 10000.00 -- 最初的数据 : 1 │ tom │ 上海 │ 25 │ 技术部 │ 20000.00 -- 聚合合并的结果: 1 │ tom │ 上海 │ 25 │ 技术部 │ 30000.00 ``` ### 五、Aggregatingmergetree表引擎 该表引擎继承自MergeTree,可以使用 `AggregatingMergeTree`表来做增量数据统计聚合。如果要按一组规则来合并减少行数,则使用 `AggregatingMergeTree`是合适的。AggregatingMergeTree是通过预先定义的聚合函数计算数据并通过二进制的格式存入表内。 与SummingMergeTree的区别在于:SummingMergeTree对非主键列进行sum聚合,而AggregatingMergeTree则可以指定各种聚合函数。 #### 建表语法 ```sql CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster] ( name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1], name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2], ... ) ENGINE = AggregatingMergeTree() [PARTITION BY expr] [ORDER BY expr] [SAMPLE BY expr] [SETTINGS name=value, ...] ``` #### 建表示例 ```sql CREATE TABLE emp_aggregatingmergeTree ( emp_id UInt16 COMMENT '员工id', name String COMMENT '员工姓名', work_place String COMMENT '工作地点', age UInt8 COMMENT '员工年龄', depart String COMMENT '部门', salary AggregateFunction(sum,Decimal32(2)) COMMENT '工资' )ENGINE=AggregatingMergeTree() ORDER BY (emp_id,name) -- 注意排序key是两个字段 PRIMARY KEY emp_id -- 主键是一个字段 PARTITION BY work_place ; ``` 对于AggregateFunction类型的列字段,在进行数据的写入和查询时与其他的表引擎有很大区别,在写入数据时,需要调用**-State**函数;而在查询数据时,则需要调用相应的**-Merge**函数。对于上面的建表语句而言,需要使用**sumState**函数进行数据插入 ```sql -- 插入数据, -- 注意:需要使用INSERT…SELECT语句进行数据插入 INSERT INTO TABLE emp_aggregatingmergeTree SELECT 1,'tom','上海',25,'信息部',sumState(toDecimal32(10000,2)); INSERT INTO TABLE emp_aggregatingmergeTree SELECT 1,'tom','上海',25,'信息部',sumState(toDecimal32(20000,2)); -- 查询数据 SELECT emp_id, name , sumMerge(salary) FROM emp_aggregatingmergeTree GROUP BY emp_id,name; -- 结果输出 ┌─emp_id─┬─name─┬─sumMerge(salary)─┐ │ 1 │ tom │ 30000.00 │ └────────┴──────┴──────────────────┘ ``` 上面演示的用法非常的麻烦,其实更多的情况下,我们可以结合物化视图一起使用,将它作为物化视图的表引擎。而这里的物化视图是作为其他数据表上层的一种查询视图。 **AggregatingMergeTree通常作为物化视图的表引擎,与普通MergeTree搭配使用。** ```sql -- 创建一个MereTree引擎的明细表 -- 用于存储全量的明细数据 -- 对外提供实时查询 CREATE TABLE emp_mergetree_base ( emp_id UInt16 COMMENT '员工id', name String COMMENT '员工姓名', work_place String COMMENT '工作地点', age UInt8 COMMENT '员工年龄', depart String COMMENT '部门', salary Decimal32(2) COMMENT '工资' )ENGINE=MergeTree() ORDER BY (emp_id,name) PARTITION BY work_place ; -- 创建一张物化视图 -- 使用AggregatingMergeTree表引擎 CREATE MATERIALIZED VIEW view_emp_agg ENGINE = AggregatingMergeTree() PARTITION BY emp_id ORDER BY (emp_id,name) AS SELECT emp_id, name, sumState(salary) AS salary FROM emp_mergetree_base GROUP BY emp_id,name; -- 向基础明细表emp_mergetree_base插入数据 INSERT INTO emp_mergetree_base VALUES (1,'tom','上海',25,'技术部',20000), (1,'tom','上海',26,'人事部',10000); -- 查询物化视图 SELECT emp_id, name , sumMerge(salary) FROM view_emp_agg GROUP BY emp_id,name; -- 结果 ┌─emp_id─┬─name─┬─sumMerge(salary)─┐ │ 1 │ tom │ 30000.00 │ └────────┴──────┴──────────────────┘ ``` ### 六、CollapsingMergeTree表引擎 CollapsingMergeTree就是一种通过以增代删的思路,支持行级数据修改和删除的表引擎。它通过定义一个sign标记位字段,记录数据行的状态。如果sign标记为1,则表示这是一行有效的数据;如果sign标记为-1,则表示这行数据需要被删除。当CollapsingMergeTree分区合并时,同一数据分区内,sign标记为1和-1的一组数据会被抵消删除。 每次需要新增数据时,写入一行sign标记为1的数据;需要删除数据时,则写入一行sign标记为-1的数据。 #### 建表语法 ```sql CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster] ( name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1], name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2], ... ) ENGINE = CollapsingMergeTree(sign) [PARTITION BY expr] [ORDER BY expr] [SAMPLE BY expr] [SETTINGS name=value, ...] ``` #### 建表示例 上面的建表语句使用CollapsingMergeTree(sign),其中字段sign是一个Int8类型的字段 ```sql CREATE TABLE emp_collapsingmergetree ( emp_id UInt16 COMMENT '员工id', name String COMMENT '员工姓名', work_place String COMMENT '工作地点', age UInt8 COMMENT '员工年龄', depart String COMMENT '部门', salary Decimal32(2) COMMENT '工资', sign Int8 )ENGINE=CollapsingMergeTree(sign) ORDER BY (emp_id,name) PARTITION BY work_place ; ``` #### 使用方式 CollapsingMergeTree同样是以ORDER BY排序键作为判断数据唯一性的依据。 ```sql -- 插入新增数据,sign=1表示正常数据 INSERT INTO emp_collapsingmergetree VALUES (1,'tom','上海',25,'技术部',20000,1); -- 更新上述的数据 -- 首先插入一条与原来相同的数据(ORDER BY字段一致),并将sign置为-1 INSERT INTO emp_collapsingmergetree VALUES (1,'tom','上海',25,'技术部',20000,-1); -- 再插入更新之后的数据 INSERT INTO emp_collapsingmergetree VALUES (1,'tom','上海',25,'技术部',30000,1); -- 查看一下结果 cdh04 :) select * from emp_collapsingmergetree ; SELECT * FROM emp_collapsingmergetree ┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┬─sign─┐ │ 1 │ tom │ 上海 │ 25 │ 技术部 │ 30000.00 │ 1 │ └────────┴──────┴────────────┴─────┴────────┴──────────┴──────┘ ┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┬─sign─┐ │ 1 │ tom │ 上海 │ 25 │ 技术部 │ 20000.00 │ -1 │ └────────┴──────┴────────────┴─────┴────────┴──────────┴──────┘ ┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┬─sign─┐ │ 1 │ tom │ 上海 │ 25 │ 技术部 │ 20000.00 │ 1 │ └────────┴──────┴────────────┴─────┴────────┴──────────┴──────┘ -- 执行分区合并操作 optimize table emp_collapsingmergetree; -- 再次查询,sign=1与sign=-1的数据相互抵消了,即被删除 cdh04 :) select * from emp_collapsingmergetree ; SELECT * FROM emp_collapsingmergetree ┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┬─sign─┐ │ 1 │ tom │ 上海 │ 25 │ 技术部 │ 30000.00 │ 1 │ └────────┴──────┴────────────┴─────┴────────┴──────────┴──────┘ ``` #### 注意点 - **分区合并** 分数数据折叠不是实时的,需要后台进行Compaction操作,用户也可以使用手动合并命令,但是效率会很低,一般不推荐在生产环境中使用。 当进行汇总数据操作时,可以通过改变查询方式,来过滤掉被删除的数据 ```sql SELECT emp_id, name, sum(salary * sign) FROM emp_collapsingmergetree GROUP BY emp_id, name HAVING sum(sign) > 0 ``` 只有相同分区内的数据才有可能被折叠。其实,当我们修改或删除数据时,这些被修改的数据通常是在一个分区内的,所以不会产生影响。 + 数据写入顺序 值得注意的是:CollapsingMergeTree对于写入数据的顺序有着严格要求,否则导致无法正常折叠。 ```sql -- 建表 CREATE TABLE emp_collapsingmergetree_order ( emp_id UInt16 COMMENT '员工id', name String COMMENT '员工姓名', work_place String COMMENT '工作地点', age UInt8 COMMENT '员工年龄', depart String COMMENT '部门', salary Decimal32(2) COMMENT '工资', sign Int8 )ENGINE=CollapsingMergeTree(sign) ORDER BY (emp_id,name) PARTITION BY work_place ; -- 先插入需要被删除的数据,即sign=-1的数据 INSERT INTO emp_collapsingmergetree_order VALUES (1,'tom','上海',25,'技术部',20000,-1); -- 再插入sign=1的数据 INSERT INTO emp_collapsingmergetree_order VALUES (1,'tom','上海',25,'技术部',20000,1); -- 查询表 SELECT * FROM emp_collapsingmergetree_order ┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┬─sign─┐ │ 1 │ tom │ 上海 │ 25 │ 技术部 │ 20000.00 │ 1 │ └────────┴──────┴────────────┴─────┴────────┴──────────┴──────┘ ┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┬─sign─┐ │ 1 │ tom │ 上海 │ 25 │ 技术部 │ 20000.00 │ -1 │ └────────┴──────┴────────────┴─────┴────────┴──────────┴──────┘ -- 执行合并操作 optimize table emp_collapsingmergetree_order; -- 再次查询表 -- 旧数据依然存在 SELECT * FROM emp_collapsingmergetree_order; ┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┬─sign─┐ │ 1 │ tom │ 上海 │ 25 │ 技术部 │ 20000.00 │ -1 │ │ 1 │ tom │ 上海 │ 25 │ 技术部 │ 20000.00 │ 1 │ └────────┴──────┴────────────┴─────┴────────┴──────────┴──────┘ ``` 如果数据的写入程序是单线程执行的,则能够较好地控制写入顺序;如果需要处理的数据量很大,数据的写入程序通常是多线程执行的,那么此时就不能保障数据的写入顺序了。在这种情况下,CollapsingMergeTree的工作机制就会出现问题。但是可以通过VersionedCollapsingMergeTree的表引擎得到解决。 ### 七、VersionedCollapsingMergeTree表引擎 上面提到CollapsingMergeTree表引擎对于数据写入乱序的情况下,不能够实现数据折叠的效果。VersionedCollapsingMergeTree表引擎的作用与CollapsingMergeTree完全相同,它们的不同之处在于,VersionedCollapsingMergeTree对数据的写入顺序没有要求,在同一个分区内,任意顺序的数据都能够完成折叠操作。 VersionedCollapsingMergeTree使用**version**列来实现乱序情况下的数据折叠。 #### 建表语法 ```sql CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster] ( name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1], name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2], ... ) ENGINE = VersionedCollapsingMergeTree(sign, version) [PARTITION BY expr] [ORDER BY expr] [SAMPLE BY expr] [SETTINGS name=value, ...] ``` 可以看出:该引擎除了需要指定一个sign标识之外,还需要指定一个UInt8类型的version版本号。 #### 建表示例 ```sql CREATE TABLE emp_versioned ( emp_id UInt16 COMMENT '员工id', name String COMMENT '员工姓名', work_place String COMMENT '工作地点', age UInt8 COMMENT '员工年龄', depart String COMMENT '部门', salary Decimal32(2) COMMENT '工资', sign Int8, version Int8 )ENGINE=VersionedCollapsingMergeTree(sign, version) ORDER BY (emp_id,name) PARTITION BY work_place ; -- 先插入需要被删除的数据,即sign=-1的数据 INSERT INTO emp_versioned VALUES (1,'tom','上海',25,'技术部',20000,-1,1); -- 再插入sign=1的数据 INSERT INTO emp_versioned VALUES (1,'tom','上海',25,'技术部',20000,1,1); -- 在插入一个新版本数据 INSERT INTO emp_versioned VALUES (1,'tom','上海',25,'技术部',30000,1,2); -- 先不执行合并,查看表数据 cdh04 :) select * from emp_versioned; SELECT * FROM emp_versioned ┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┬─sign─┬─version─┐ │ 1 │ tom │ 上海 │ 25 │ 技术部 │ 30000.00 │ 1 │ 2 │ └────────┴──────┴────────────┴─────┴────────┴──────────┴──────┴─────────┘ ┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┬─sign─┬─version─┐ │ 1 │ tom │ 上海 │ 25 │ 技术部 │ 20000.00 │ 1 │ 1 │ └────────┴──────┴────────────┴─────┴────────┴──────────┴──────┴─────────┘ ┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┬─sign─┬─version─┐ │ 1 │ tom │ 上海 │ 25 │ 技术部 │ 20000.00 │ -1 │ 1 │ └────────┴──────┴────────────┴─────┴────────┴──────────┴──────┴─────────┘ -- 获取正确查询结果 SELECT emp_id, name, sum(salary * sign) FROM emp_versioned GROUP BY emp_id, name HAVING sum(sign) > 0; -- 手动合并 optimize table emp_versioned; -- 再次查询 cdh04 :) select * from emp_versioned; SELECT * FROM emp_versioned ┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┬─sign─┬─version─┐ │ 1 │ tom │ 上海 │ 25 │ 技术部 │ 30000.00 │ 1 │ 2 │ └────────┴──────┴────────────┴─────┴────────┴──────────┴──────┴─────────┘ ``` 可见上面虽然在插入数据乱序的情况下,依然能够实现折叠的效果。之所以能够达到这种效果,是因为在定义version字段之后,VersionedCollapsingMergeTree会自动将version作为排序条件并增加到ORDER BY的末端,就上述的例子而言,最终的排序字段为ORDER BY emp_id,name,version desc。 ### 八、GraphiteMergeTree表引擎 该引擎用来对 Graphite数据进行'瘦身'及汇总。对于想使用CH来存储Graphite数据的开发者来说可能有用。 如果不需要对Graphite数据做汇总,那么可以使用任意的CH表引擎;但若需要,那就采用 GraphiteMergeTree 引擎。它能减少存储空间,同时能提高Graphite数据的查询效率。
标签:
ClickHouse
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://lilinchao.com/archives/2035.html
上一篇
【转载】04.ClickHouse表引擎之Log系列表引擎
下一篇
【转载】06.ClickHouse表引擎之外部集成表引擎
评论已关闭
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
NLP
4
标签云
Java阻塞队列
FastDFS
数据结构
Golang基础
MyBatis
VUE
LeetCode刷题
高并发
MySQL
微服务
Kibana
Spark Core
Zookeeper
Redis
并发编程
Hive
SpringBoot
Jquery
设计模式
数据结构和算法
持有对象
ClickHouse
Azkaban
Spark
GET和POST
机器学习
Python
Stream流
Java
稀疏数组
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞
评论已关闭