03.NIO之bytebuffer内部结构和方法
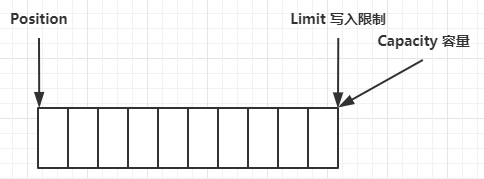
[TOC]一、bytebuffer内部结构1.1 属性介绍Bytebuffer有以下重要属性:capacity(容量):缓冲区的容量。通过构造函数赋予,一旦设置,无法更改。position(指针):读写指针,记录数据读写的位置,缓冲区的位置不能为负,并且不能大于limit。limit(读写限制):缓冲区的界限。位于limit 后的数据不可读写。缓冲区的限制不能为负,并且不能大于其容量。1.2 结构写模式当缓冲区刚创建成功时写模式下,position 是写入位置,limit 等于容量。下图表示写入了 4 个字节后的状态:Position移动到第5个字节开始位置读模式flip动作发生后,po...
02.NIO之bytebuffer基本使用
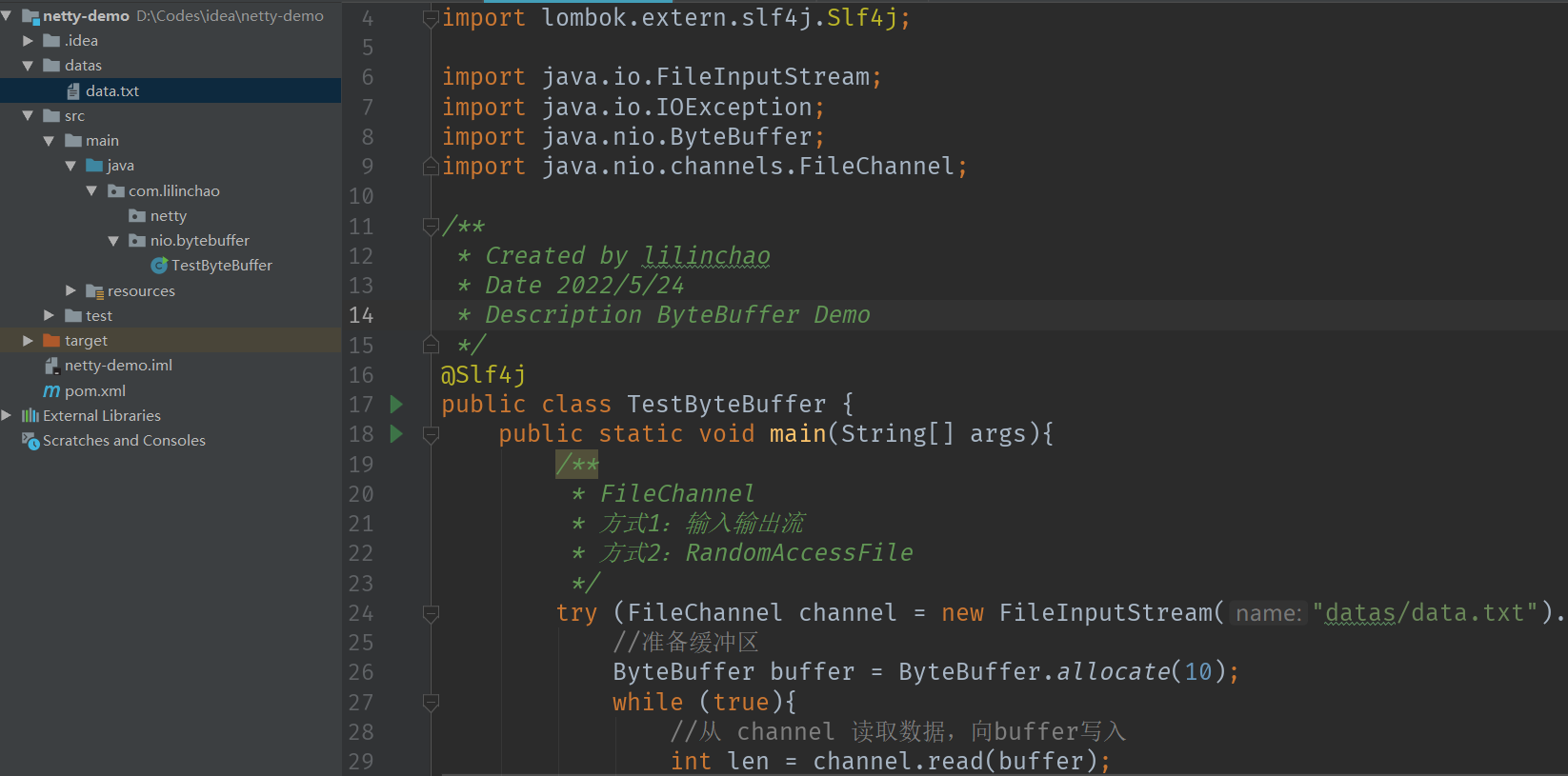
[TOC]前言本篇将通过nio读取一个文本文件来演示bytebuffer的基本使用一、准备数据准备创建data.txt文件,增加如下内容:1234567890abcd创建Maven项目安装lomback插件二、ByteBuffer 使用分析向 buffer 写入数据,例如调用 channel.read(buffer)调用 flip() 切换至读模式从 buffer 读取数据,例如调用 buffer.get()调用 clear() 或 compact() 切换至写模式重复 1~4 步骤三、代码实现引入pom依赖<properties> <maven.compile...
01.NIO简单介绍
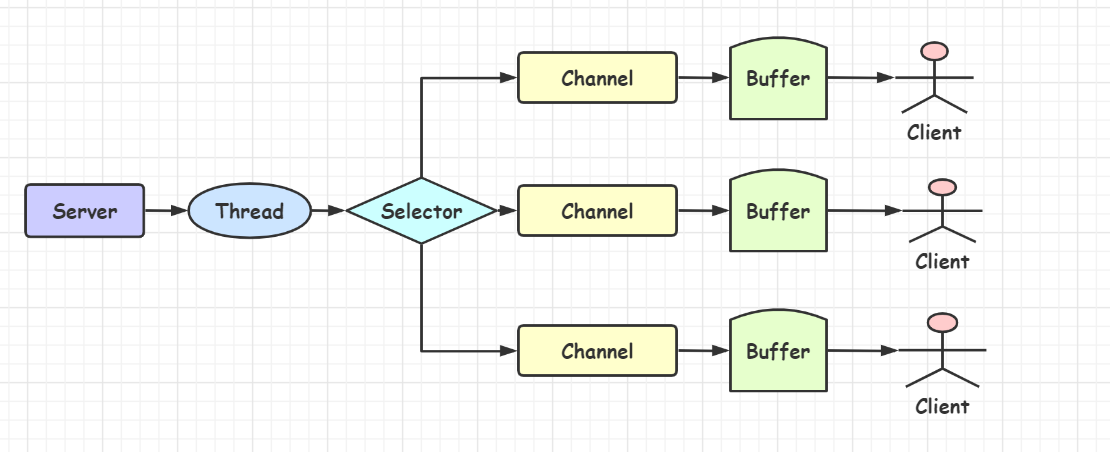
[TOC]前言Java NIO有两种解释:一种叫非阻塞IO(Non-blocking I/O)另一种叫新的IO(New I/O)其实两种概念也是相同的。一、概述Java NIO是从Java1.4版本开始引入的一个新的IO API,可以代替标准的IO API。NIO与原来的IO有同样的作用和目的,但是使用的方式完全不同,NIO支持面向缓冲区的,基于通道的IO操作。NIO将以更加高效的方式进行文件的读写操作。NIO有三大核心部分Channel(通道)Buffer(缓冲区)Selector(选择器)二、Java NIO与BIO的区别BIO以流的方式处理数据,而NIO以块的方式处理数据,块IO的...
13.ClickHouse之MaterializeMySQL引擎
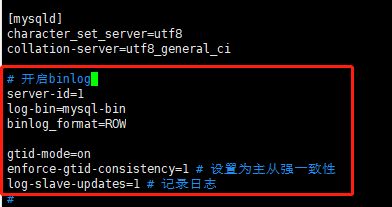
[TOC]前言MaterializeMySQL号称ClickHouse的王炸功能,本篇文章将结合具体示例来对MaterializeMySQL进行一个介绍本篇示例版本ClickHouse 21.7.3.14-2MySQL 8.0.23一、概述 MySQL 的用户群体很大,为了能够增强数据的实时性,很多解决方案会利用 binlog 将数据写入到 ClickHouse。为了能够监听 binlog 事件,我们需要用到类似 canal 这样的第三 方中间件,这无疑增加了系统的复杂度。 ClickHouse 20.8.2.3 版本新增加了 MaterializeMyS...

12.ClickHouse之物化视图
[TOC]前言 ClickHouse 的物化视图是一种查询结果的持久化,它确实是给我们带来了查询效率的提升。用户查起来跟表没有区别,它就是一张表,它也像是一张时刻在预计算的表,创建的过程它是用了一个特殊引擎,加上后来 as select,就是 create 一个 table as select 的写法。 “查询结果集”的范围很宽泛,可以是基础表中部分数据的一份简单拷贝,也可以是多表 join 之后产生的结果或其子集,或者原始数据的聚合指标等等。所以,物化视图不会随着基础表的变化而变化,所以它也称为快照(snapshot)。一、概述1.1 物化视图与普通视图...

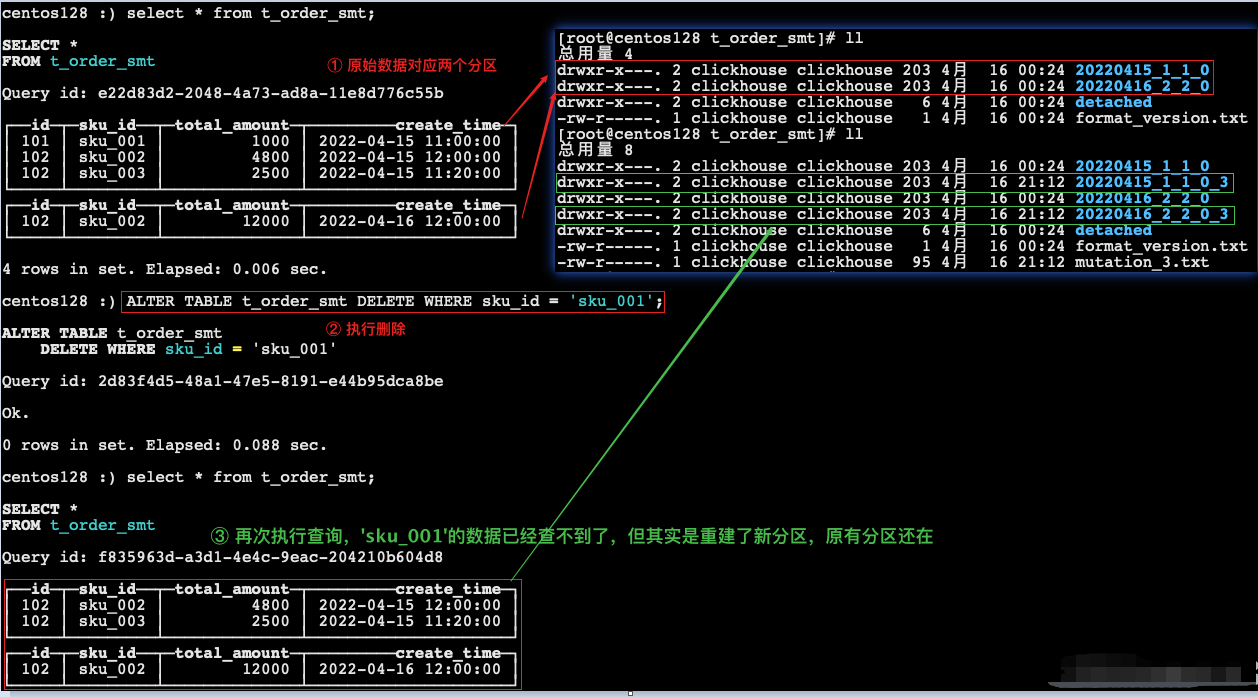
11.ClickHouse之数据一致性
[TOC]一、概述查询 CK 手册发现,即便对数据一致性支持最好的 Mergetree,也只是保证最终一致性:我们在使用 ReplacingMergeTree、SummingMergeTree 这类表引擎的时候,会出现短暂数据不一致的情况。在某些对一致性非常敏感的场景,通常有以下几种解决方案。二、准备测试表和数据(1)创建表CREATE TABLE test_a( user_id UInt64, score String, deleted UInt8 DEFAULT 0, create_time DateTime DEFAULT toDateTime(0)...
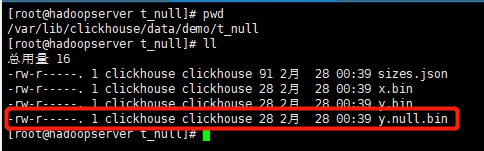
10.ClickHouse建表优化
[TOC]一、数据类型1. 时间字段的类型 建表时能用数值型或日期时间型表示的字段就不要用字符串,全String类型在以Hive为中心的数仓建设中常见,但ClickHouse环境不应受此影响。 虽然ClickHouse底层将DateTime存储为时间戳Long类型,但不建议存储 Long 类型, 因为 DateTime不需要经过函数转换处理,执行效率高、可读性好。create table t_type2( id UInt32, sku_id String, total_amount Decimal(16,2), create...
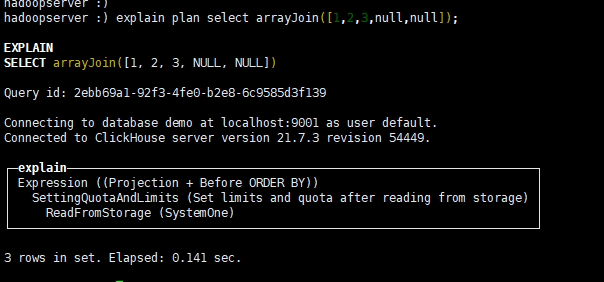
09.ClickHouse查看执行计划
[TOC]一、概述 在clickhuse20.6版本之前要查看SQL语句的执行计划需要设置日志级别为trace才能可以看到,并且只能真正执行sql,在执行日志里面查看。在20.6版本引入了原生的执行计划的语法。在20.6.3版本成为正式版本的功能。二、基本语法EXPLAIN [AST | SYNTAX | PLAN | PIPELINE] [setting = value, ...] select ...[FORMAT ...]PLAN:用于查看执行计划,默认值。header:打印计划中各个步骤的head说明,默认关闭,默认值 0;description:打印计划中各个...
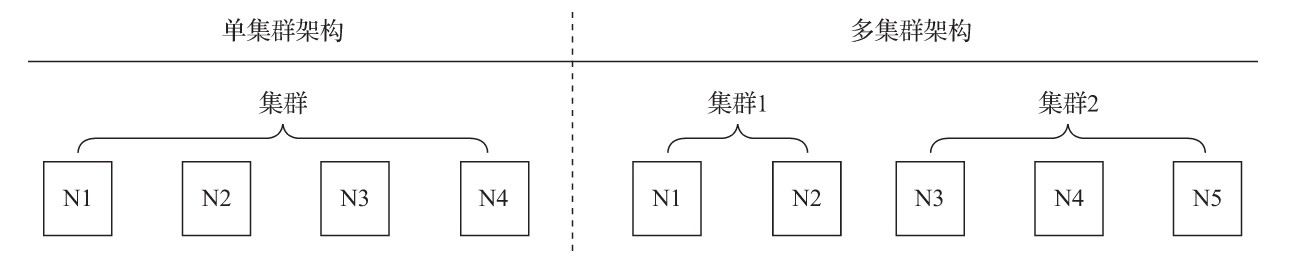
08.ClickHouse副本和分片介绍
08.ClickHouse副本和分片介绍一、概述集群是副本和分片的基础,它将ClickHouse的服务拓扑由单节点延伸到多个节点,但它并不像Hadoop生态的某些系统那样,要求所有节点组成一个单一的大集群。ClickHouse的集群配置非常灵活,用户既可以将所有节点组成一个单一集群,也可以按照业务的诉求,把节点划分为多个小的集群。在每个小的集群区域之间,它们的节点、分区和副本数量可以各不相同,如图所示。从作用来看,ClickHouse集群的工作更多是针对逻辑层面的。集群定义了多个节点的拓扑关系,这些节点在后续服务过程中可能会协同工作,而执行层面的具体工作则交给了副本和分片来执行。副本和分...
07.ClickHouse之SQL操作
[TOC]前言基本上来说传统关系型数据库(以 MySQL 为例)的 SQL 语句,ClickHouse 基本都支持, 这里不会从头讲解 SQL 语法只介绍 ClickHouse 与标准 SQL(MySQL)不一致的地方。一、CREATE1.1 创建数据库#用于创建指定名称的数据库 CREATE DATABASE [IF NOT EXISTS] db_name;1.2 创建数据表语法如下CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster] ( name1 [type1] [DEFAULT|MATERIAL...