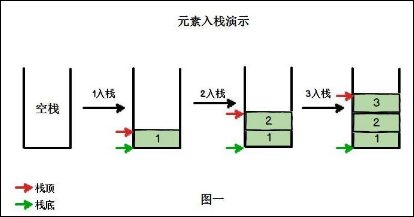
Scala栈练习
Scala栈练习一、概念详情可参考文章:数据结构学习--栈(一)栈(stack)就像弹夹一样,是先入后出的有序列表栈(stack)是限制线性表中元素的插入和删除只能在线性表的同一端进行的一种特殊线性表。允许插入和删除的一端,为变化的一端,称为栈顶(Top),另一端为固定的一端,称为栈底(Bottom)。根据堆栈的定义可知,最先放入栈中元素在栈底,最后放入的元素在栈顶,而删除元素刚好相反,最后...

Scala单向链表练习
Scala单向链表练习一、概念单向链表的定义可参考文章:数据结构学习--链表二、代码单向链表objectobject SingleLinkedListDemo01 { def main(args: Array[String]): Unit = { // 测试单向链表的添加和遍历 val heroNode1 = new HeroNode(1, "宋江"...
Scala队列练习
Scala队列练习一、概念介绍基于队列概念介绍可参考文章:数据结构学习--队列(一)基于环形队列概念介绍可参考文章:数据结构学习--环形队列(二)本文将不在进行过多赘述二、代码2.1 数组模拟单向队列objectimport scala.io.StdIn object ArrayQueueDemo01 { def main(args: Array[String]): Unit = { ...
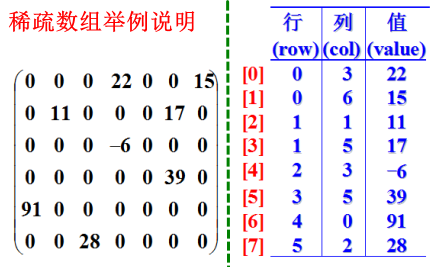
Scala稀疏数组练习
18.Scala稀疏数组练习一、概念当一个数组中大部分元素为 0,或者为同一个值的数组时,可以使用稀疏数组来保存该数组。稀疏数组的处理方法:记录数组一共有几行几列,有多少个不同的值。把具有不同值的元素的行列及值记录在一个小规模的数组中,从而缩小程序的规模。稀疏数组举例说明二、应用实例描述使用稀疏数组,来保留类似前面的二维数组(棋盘、地图等等)。把稀疏数组存盘,并且可以重新恢复原来的二维数组数...
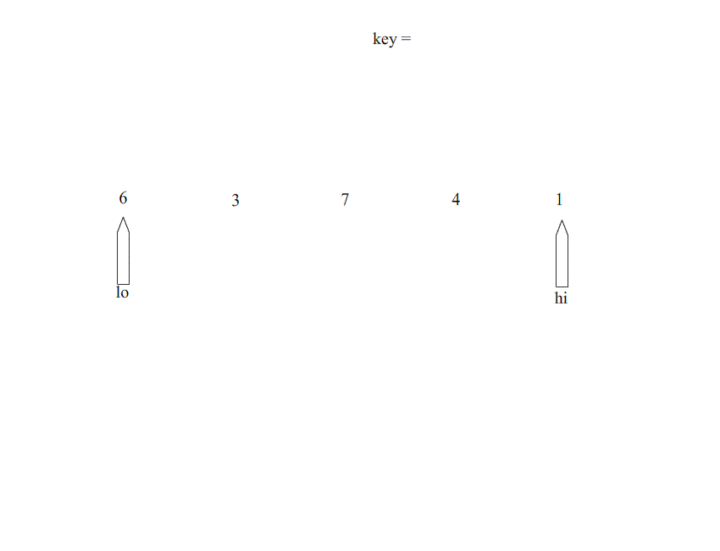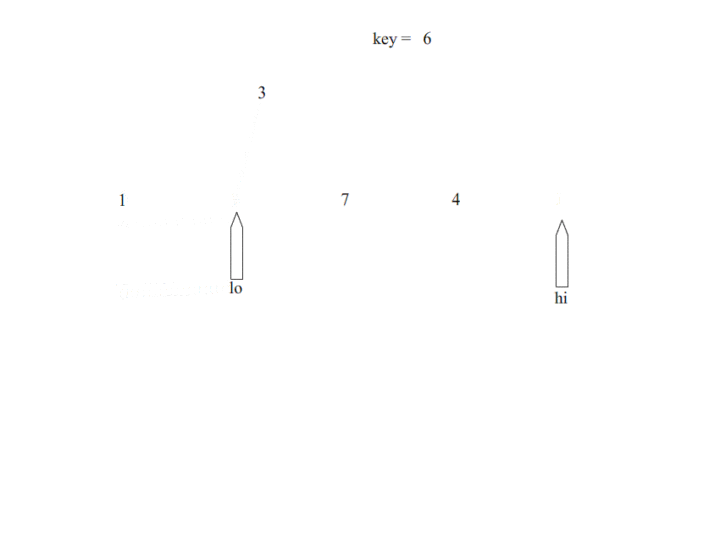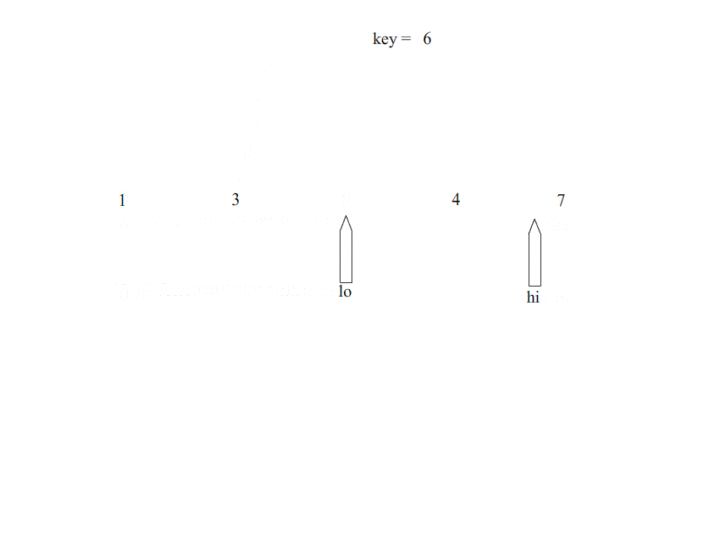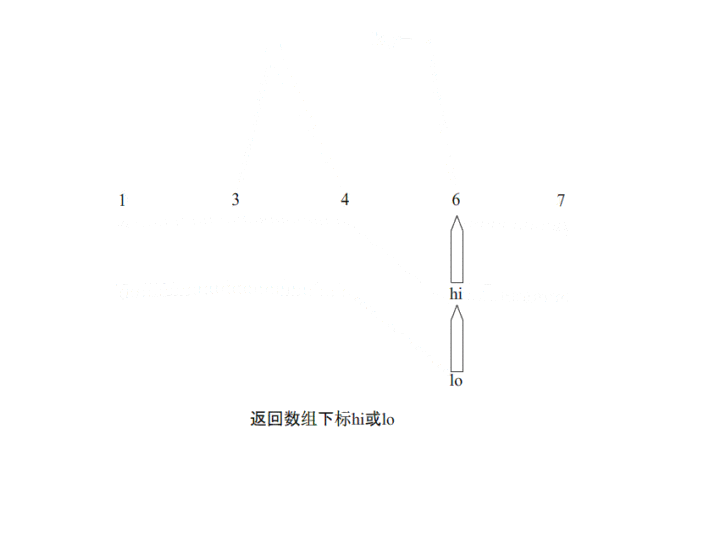
Scala练习(一)
Scala练习(一)前言学习程序重要的是学习其中的思想一、scala实现快速排序快速排序介绍思想:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。1.1 一次快速排序分析快速排序使用的二分的思想首先选择一个基准,定义左右两端指针,先从左到右进...
Spark读写HBase实践
Spark读写HBase实践前言Spark经常会读写一些外部数据源,常见的有HDFS、HBase、JDBC、Redis、Kafka等。一、maven依赖需要引入Hadoop和HBase的相关依赖,版本信息根据实际情况确定。<properties> <spark.version>2.4.4</spark.version> &l...
Scala总结(二)--函数
14.Scala总结(二)--函数一、函数的声明和调用1.1 函数的声明格式权限修饰符 函数名 (参数列表) : 返回值类型 = { 函数体 }案例:def func(i:Int) : Unit = { println(i) }1.2 函数的调用函数名(形参类表)二、函数的定义一共有如下6种情况:无参 --> 无返回值、有返回值 有参 --> 无返回值、有...
Scala总结(三)
15.Scala总结(三)一、字符串操作object Scala_String_Test { def main(args: Array[String]): Unit = { val s1 = "Hello" val s2 = "Scala" //拼接、合并字符串 println(s1 + " "...
Scala总结(一)
13.Scala总结(一)一、基础1.1 数据类型Scala 与 Java有着相同的数据类型,下表列出了 Scala 支持的数据类型:数据类型描述Byte8位有符号补码整数。数值区间为 -128 到 127Short16位有符号补码整数。数值区间为 -32768 到 32767Int32位有符号补码整数。数值区间为 -2147483648 到 2147483647Long64位有符号补码整...