李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
Java
正文
43.ThreadPoolExecutor线程池状态和构造方法
Leefs
2022-11-17 PM
1071℃
0条
[TOC] ### 一、概述 #### 1.1 线程池的作用 **线程池技术就是线程的重用技术,使用已经创建好的线程来执行当前任务,并提供了针对线程周期开销和资源冲突问题的解决方案。** 由于请求到达时线程已经存在,因此消除了线程创建过程导致的延迟,使应用程序得到更快的响应。 #### 1.2 线程池的好处 + 使用线程池可以重复利用已有的线程继续执行任务,避免线程在创建和销毁时造成的消耗; + 由于没有线程创建和销毁时的消耗,可以提高系统响应速度; + 通过线程池可以对线程进行合理的管理,根据系统的承受能力调整可运行线程数量的大小等。 #### 1.3 线程池的结构 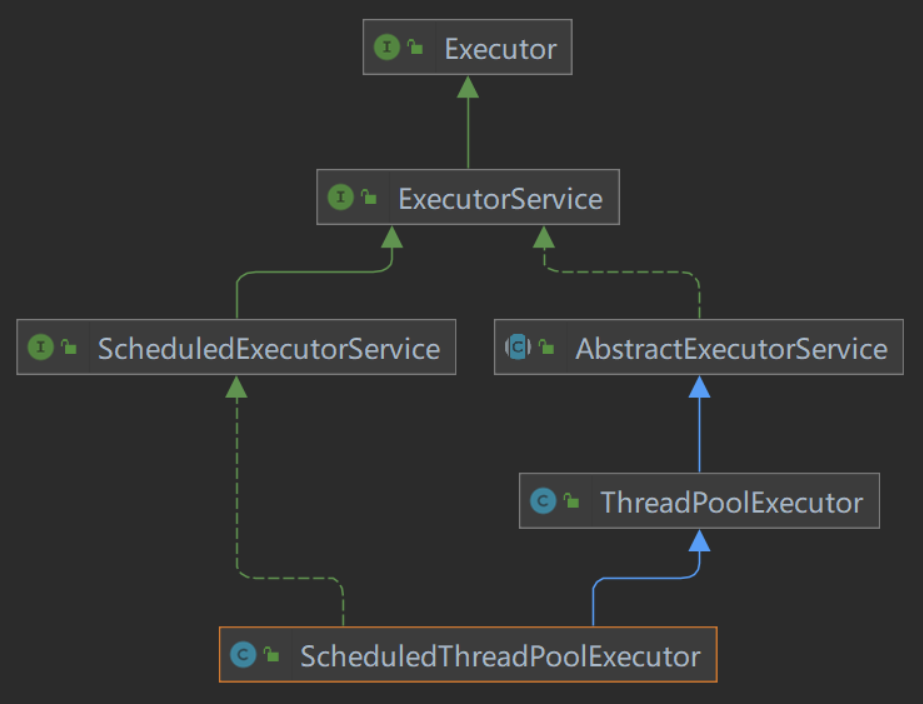 **说明** + **Executor**:线程池相关顶级接口,是 Java 异步任务目标的“执行者”接口,其目标是执行目标任务。只定义了一个`execute()`方法(void execute(Runnable command);),只能提交Runnable形式的任务,不支持提交Callable带有返回值的任务。 `Executor`作为执行者的角色,其目的是提供一种将“任务提交者”与“任务执行者”分离开来的机制。 + **ExecutorService**:继承并扩展了Executor接口,在Executor的基础上加入了线程池的生命周期管理,可以通过`shutdown`或者`shutdownNow`方法来关闭线程池。`ExecutorService`支持提交Callable形式的任务,提交完Callable任务后拿到一个Future(代表一个异步任务执行的结果)。 + **AbstarctExecutorService**:是一个抽象类,它实现了 `ExecutorService` 接口,为 `ExecutorService` 接口中的方法提供默认实现。 + **ThreadPoolExecutor**:线程池中最核心的类,用来执行被提交的任务,后面会详细介绍。 + **ScheduledExecutorService**:继承`ExecutorService`接口,并定义延迟或定期执行的方法。 + **ScheduledThreadPoolExecutor**:ThreadPoolExecutor子类,它在ThreadPoolExecutor基础上加入了任务定时执行的功能。 ### 二、线程池状态 线程存在生命周期,同样线程池也有生命周期,源码中定义了五种状态。 ```java private static final int RUNNING = -1 << COUNT_BITS; private static final int SHUTDOWN = 0 << COUNT_BITS; private static final int STOP = 1 << COUNT_BITS; private static final int TIDYING = 2 << COUNT_BITS; private static final int TERMINATED = 3 << COUNT_BITS; ``` `ThreadPoolExecutor` 使用 int 的高 3 位来表示线程池状态,低 29 位表示线程数量 | 状态名 | 高3位 | 接收新任务 | 处理阻塞任务队列 | 说明 | | ---------- | ----- | ---------- | ---------------- | ------------------------------------------------------------ | | RUNNING | 111 | Y | Y | 能接受新提交的任务,并且也能处理阻塞队列中的任务 | | SHUTDOWN | 000 | N | Y | 关闭状态,不会接收新任务,但会处理阻塞队列剩余任务 | | STOP | 001 | N | N | 不能接受新任务,也不处理队列中的任务,会中断正在处理任务的线程,并抛弃阻塞队列任务 | | TIDYING | 010 | - | - | 任务全执行完毕,活动线程为 0 即将进入终结 | | TERMINATED | 011 | - | - | 终结状态 | + **线程池生命周期示意图**  **说明** + 刚开始线程处于**RUNNING**状态,能接受新提交的任务,并且也能处理阻塞队列中的任务; + 当调用了线程池的shutdown()方法进入到**SHUTDOWN**状态,此时**意图**停止线程池,它是一种比较温和的,正在执行的任务和阻塞队列中的任务,都不会取消掉,等这些任务都被处理掉后,线程池才会关闭,但是调用了shutdown()以后,就不会再接收新任务了; + 当调用了线程池中的`shutdownNow()`方法,此时进入到**STOP**状态,暴力停止线程池,不会接收新任务,正在执行的任务也会被打断(通过调用interrupt()来打断),阻塞队列的任务也会被抛弃掉; + TIDYING状态是一个过渡状态,当任务全部执行完毕,活动的线程也为0了,线程池即将进入TERMINATED状态; + TERMINATED状态的线程池已经不能工作了,处于终结状态。 从数字上比较:`TERMINATED > TIDYING > STOP > SHUTDOWN > RUNNING`(RUNNING为负数,因为是高三位,最高位为符号位) 为了保证状态信息以及线程数量在赋值时的原子性;他们被存储在一个原子变量ctl中,目的是将线程池状态与线程个数合二为一,这样就可以用一次cas原子操作进行赋值。 ```java // c为旧值,ctlOf返回结果为新值 ctl.compareAndSet(c, ctlOf(targetState, workCountOf(c))); // rs为高3位,代表线程池状态,wc为低29位代表线程个数,ctlOf是合并他们 private static int ctlOf(int rs, int wc){return rs | wc;} ``` ### 三、ThreadPoolExecutor构造方法 ```java public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) { if (corePoolSize < 0 || maximumPoolSize <= 0 || maximumPoolSize < corePoolSize || keepAliveTime < 0) throw new IllegalArgumentException(); if (workQueue == null || threadFactory == null || handler == null) throw new NullPointerException(); this.acc = System.getSecurityManager() == null ? null : AccessController.getContext(); this.corePoolSize = corePoolSize; this.maximumPoolSize = maximumPoolSize; this.workQueue = workQueue; this.keepAliveTime = unit.toNanos(keepAliveTime); this.threadFactory = threadFactory; this.handler = handler; } ``` **ThreadPoolExecutor包含了7个核心参数**: + `maximumPoolSize`:最大线程池的大小 + `keepAliveTime`:当线程池中线程数大于`corePoolSize`,并且没有可执行任务时大于`corePoolSize`那部分线程的存活时间 + `unit`:`keepAliveTime`的时间单位 + `workQueue`:用来暂时保存任务的工作队列 + `threadFactory`:线程工厂提供线程的创建方式,默认使用`Executors.defaultThreadFactory()` + `handler`:当线程池所处理的任务数超过其承载容量或关闭后继续有任务提交时,所调用的拒绝策略 #### 核心参详解 ThreadPoolExecutor中包含了七大核心参数,如果需要对线程池进行定制化操作,需要对其中比较核心的参数进行一定程度的认识。 ##### corePoolSize `ThreadPoolExecutor`会根据`corePoolSize`和`maximumPoolSize`在构造方法中设置的边界值自动调整池大小,也可以使用`setCorePoolSize`和`setMaximumPoolSize`动态更改,关于线程数量的自动调整分为以下两种场景: - **线程数量小于`corePoolSize`** 当在线程池中提交了一个新任务,并且运行的线程少于`corePoolSize`时,即使其他工作线程处于空闲状态,也会创建一个新线程来处理该请求。 - **线程数量介于`corePoolSize`和`maximumPoolSize`之间** 如果运行的线程数多于`corePoolSize`但少于`maximumPoolSize`,则仅当队列已满时才会创建新线程。 如果`corePoolSize`和`maximumPoolSize`相同,那么可以创建一个固定大小的线程池。如果`maximumPoolSize`被设置为无界值(`Integer.MAX_VALUE`),在资源允许的前提下,意味着线程池允许容纳任意数量的并发任务。 默认情况下,即使是核心线程也会在新任务到达时开始创建和启动,如果使用非空队列创建线程池,可以通过重写`prestartCoreThread`或`prestartAllCoreThreads`方法动态覆盖,进行线程预启动。 在实际开发中,如果需要自定义线程数量,可以参考以下公式:  **其中参数含义如下**: - *Ncpu*是处理器的核数目,可以通过`Runtime.getRuntime().availableProcessors()`获得 - *Ucpu*是期望的CPU利用率,介于0-1之间 - W/C是等待时间与计算时间的比率 ##### keepAliveTime + `keepAliveTime`参数用来设置空闲时间。 + 如果池当前有多个`corePoolSize`线程,多余的线程如果空闲时间超过将会被终止,这种机制减少了在任务数量较少时线程池资源消耗。 + 如果某个时间需要处理的任务数量增加,则将构造新线程。 + 使用方法`setKeepAliveTime`可以动态更改参数值。 默认情况下,`keep-alive`策略仅适用于超过`corePoolSize`线程的情况,但是方法`allowCoreThreadTimeOut`也可用于将此超时策略应用于核心线程,只要 keepAliveTime值不为零即可。 ##### workQueue workQueue参数用来指定存放提交任务的队列,任何`BlockingQueue`都可以用来传输和保存提交的任务。 **关于队列大小与线程数量之间存在这样的关系**: + 如果线程数少于`corePoolSize`,对于提交的新任务会创建一个新的线程处理,并不会把任务放入队列; + 如果线程数介于`corePoolSize`和`maximumPoolSize`之间,新提交的任务会被放入阻塞队列中; + 如果线程池处于饱和状态,即无法创建线程也无法存放在阻塞队列,那么新任务将交由拒绝策略来处理。 线程池中的常用阻塞队列一般包含`SynchronousQueue`、`LinkedBlockingQueue`、`ArrayBlockingQueue`几种,它们都是`BlockingQueue`的实现类。 **下面进行简单介绍**: + **SynchronousQueue(直接提交队列)** + `SynchronousQueue`并不能算得上一个真正的队列,虽然实现了`BlockingQueue`接口,但是并没有容量,不能存储任务。只是维护一组线程,在等待着把元素加入或移出队列,相当于直接交接任务给具体执行的线程。 + 如果没有立即可用的线程来运行任务,则尝试将任务排队失败,因此将构造一个新线程。 + 在处理可能具有内部依赖关系的请求集时,此策略可避免锁定。 + 这种队列方式通常需要无限的`maximumPoolSizes`以避免拒绝新提交的任务。 + 当任务提交的平均到达速度快于线程处理速度时,线程存在无限增长的可能性,而`CachedThreadPool`正式采用这种形式。 + **LinkedBlockingQueue(无界的任务队列)** + `LinkedBlockingQueue`是采用链表实现的无界队列,如果使用没有预定义容量的`LinkedBlockingQueue`,当所有`corePoolSize`线程都在处理任务时,将导致新任务都会在队列中等待,不会创建超过`corePoolSize`个线程。 这种场景下`maximumPoolSize`的值对于线程数量没有任何影响。 + 这种依托队列处理任务的方式恰与`SynchronousQueue`依托线程处理任务的方式相反。 + **ArrayBlockingQueue(有界的任务队列)** + `ArrayBlockingQueue`是通过数组实现的有界队列。 + 有界队列在与有限的`maximumPoolSizes`一起使用时有助于防止资源耗尽,但可能更难以调整和控制。 + 使用`ArrayBlockingQueue`可以根据应用场景,预先估计池和队列的容量,互相权衡队列大小和最大池大小: + **使用大队列和小池**:减少线程数量,可以最大限度地减少CPU使用率、操作系统资源和上下文切换开销,但可能会导致吞吐量降低 + **使用小队列大池**:较大数量的线程,如果任务提交速度过快,会在短时间内提升CPU使用率,理论上可以提高系统的吞吐量。如果任务经常阻塞(如受到IO限制),会使得CPU切换更加频繁,可能会遇到更大的调度开销,这也会降低吞吐量 + **PriorityBlockingQueue(优先任务队列)** + `PriorityBlockingQueue`其实是一个特殊的无界队列,它其中无论添加了多少个任务,线程池创建的线程数也不会超过corePoolSize的数量。 + 只不过其他队列一般是按照先进先出的规则处理任务,而`PriorityBlockingQueue`队列可以自定义规则根据任务的优先级顺序先后执行。 ##### threadFactory + 该参数提供了线程池中线程的创建方式,这里使用了工厂模式`ThreadFactory`创建新线程。 + 默认情况下,会使用 `Executors.defaultThreadFactory`,它创建的线程都在同一个`ThreadGroup`中,并具有相同的`NORM_PRIORITY`优先级和非守护进程状态。 + 也可以根据实际场景自定义`ThreadFactory`,可以更改线程的名称、线程组、优先级、守护程序状态等; + 在自定义情况下需要注意的是如果`ThreadFactory`在从`newThread`返回null时未能创建线程,则执行程序将继续,但可能无法执行任何任务。 + 线程应该拥有“`modifyThread`”`RuntimePermission`。 + 如果工作线程或其他使用该池的线程不具备此权限,则服务可能会降级:配置更改可能无法及时生效,关闭池可能会一直处于可以终止但未完成的状态。 ##### handler 如果线程池处于饱和状态,没有足够的线程数或者队列空间来处理提交的任务,或者是线程池已经处于关闭状态但还在处理进行中的任务,那么继续提交的任务就会根据线程池的拒绝策略处理。 无论哪种情况,execute方法都会调用其`RejectedExecutionHandler`的`rejectedExecution`方法。 **线程池中提供了四个预定义的处理程序策略**: - **ThreadPoolExecutor.AbortPolicy** (默认):该策略会直接抛出异常,阻止系统正常工作 。 - **ThreadPoolExecutor.DiscardPolicy**:该策略会默默丢弃无法处理的任务,不予任何处理。当然使用此策略,业务场景中需允许任务的丢失。 - **ThreadPoolExecutor.DiscardOldestPolicy**:该策略会丢弃任务队列中最老的一个任务,也就是当前任务队列中最先被添加进去的,马上要被执行的那个任务,并尝试再次提交。 - **ThreadPoolExecutor.CallerRunsPolicy**:如果线程池的线程数量达到上限,该策略会把任务队列中的任务放在调用者线程当中运行。 这些预定义策略都实现了`RejectedExecutionHandler`接口,也可以定义实现类重写拒绝策略。 #### 线程池核心组成  **线程池包含 3 个核心部分**: - **线程集合**:核心线程和工作线程 - **阻塞队列**:用于待执行任务排队 - **拒绝策略处理器**:阻塞队列满后,对任务处理进行 #### 执行流程 + 线程池中刚开始没有线程,当一个任务提交给线程池后,线程池会创建一个新线程来执行任务。 + 当线程数达到 `corePoolSize` 并没有线程空闲,这时再加入任务,新加的任务会被加入`workQueue` 队列排队,直到有空闲的线程。 + 如果队列选择了有界队列,那么任务超过了队列大小时,会创建 `maximumPoolSize - corePoolSize` 数目的线程来救急。 + 如果线程到达 `maximumPoolSize` 仍然有新任务这时会执行拒绝策略。 + 当高峰过去后,超过`corePoolSize` 的救急线程如果一段时间没有任务做,需要结束节省资源,这个时间由`keepAliveTime` 和 unit 来控制。 **拒绝策略 jdk 提供了 4 种实现**: - `AbortPolicy`:让调用者抛出 `RejectedExecutionException` 异常,这是默认策略 - `CallerRunsPolicy`:让调用者运行任务 - `DiscardPolicy`:放弃本次任务 - `DiscardOldestPolicy`:放弃队列中最早的任务,本任务取而代之 **其它著名框架也提供了实现**: + `Dubbo` 的实现,在抛出 `RejectedExecutionException` 异常之前会记录日志,并 dump 线程栈信息,方便定位问题 + Netty 的实现,是创建一个新线程来执行任务 + `ActiveMQ` 的实现,带超时等待(60s)尝试放入队列,类似我们之前自定义的拒绝策略 + `PinPoint` 的实现,它使用了一个拒绝策略链,会逐一尝试策略链中每种拒绝策略 ### 四、Execute 原理 当一个新任务提交至线程池之后,线程池的处理流程如下:  1. 首先判断当前运行的线程数量是否小于 **corePoolSize**。如果是,则创建一个工作线程来执行任务;如果都在执行任务,则进入步骤 2。 2. 判断 `BlockingQueue` 是否已经满了,若没满,则将任务放入 `BlockingQueue`;若满了,则进入步骤 3。 3. 判断当前运行的总线程数量是否小于 **maximumPoolSize**,如果是则创建一个新的工作线程来执行任务。 4. 否则交给 **RejectedExecutionHandler** 来处理任务。 > 当 ThreadPoolExecutor 创建新线程时,通过 CAS 来更新线程池的状态 ctl。 *附参考文章链接* *https://blog.csdn.net/qq_38721537/article/details/124565092* *https://blog.csdn.net/ffella/article/details/126061817*
标签:
并发编程
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://lilinchao.com/archives/2583.html
上一篇
42.并发编程之自定义线程池
下一篇
44.Executors创建线程池方法介绍
评论已关闭
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
NLP
4
标签云
线程池
MyBatis-Plus
哈希表
FastDFS
JavaWeb
Netty
二叉树
Shiro
Scala
Docker
并发编程
Jquery
RSA加解密
Spark SQL
人工智能
FileBeat
Python
Java编程思想
Hadoop
Livy
字符串
JavaSE
SQL练习题
CentOS
Java
DataX
SpringBoot
MyBatis
pytorch
Thymeleaf
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞
评论已关闭