李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
Java
正文
40.并发编程之享元模式
Leefs
2022-11-12 PM
1161℃
0条
[TOC] ### 前言 小编之前转载过一篇文章*[《设计模式之享元模式》](https://lilinchao.com/archives/393.html)*在开始本节之前,如果之前没有接触过这个概念的,建议可以先看一下,对享元模式有一个基本的认识。 ### 一、简介 #### 1.1 定义 **享元模式(Flyweight Pattern)**:**运用共享技术有效地支持大量细粒度对象的复用**。 系统只使用少量的对象,而这些对象都很相似,状态变化很小,可以实现对象的多次复用。由于享元模式要求能够共享的对象必须是细粒度对象,因此它又称为轻量级模式。 在享元模式中可以共享的相同内容称为内部状态(`IntrinsicState`),而那些需要外部环境来设置的不能共享的内容称为外部状态(Extrinsic State),由于区分了内部状态和外部状态,因此可以通过设置不同的外部状态使得相同的对象可以具有一些不同的特征,而相同的内部状态是可以共享的。 #### 1.2 优缺点 **优点** - 享元模式的优点在于它可以极大减少内存中对象的数量,使得相同对象或相似对象在内存中只保存一份。 - 享元模式的外部状态相对独立,而且不会影响其内部状态,从而使得享元对象可以在不同的环境中被共享。 **缺点** - 享元模式使得系统更加复杂,需要分离出内部状态和外部状态,这使得程序的逻辑复杂化。 - 为了使对象可以共享,享元模式需要将享元对象的状态外部化,而读取外部状态使得运行时间变长。 #### 1.3 使用场景 - 一个系统有大量相同或者相似的对象,由于这类对象的大量使用,造成内存的大量耗费。 - 对象的大部分状态都可以外部化,可以将这些外部状态传入对象中。 - 使用享元模式需要维护一个存储享元对象的享元池,而这需要耗费资源,因此,应当在多次重复使用享元对象时才值得使用享元模式。 ### 二、结构 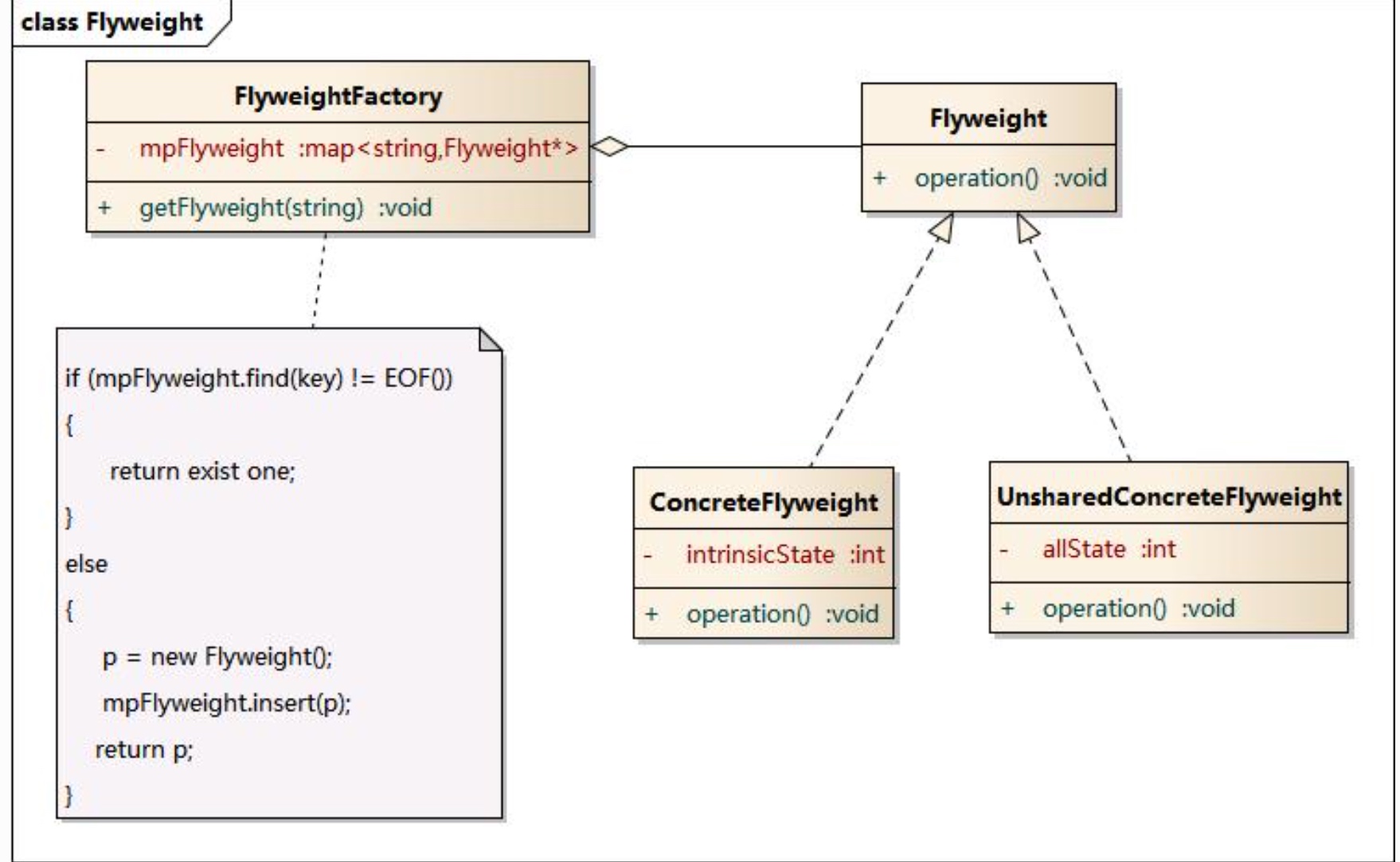 **享元模式的主要角色**: - **抽象享元角色(Flyweight)**:是所有的具体享元类的基类,为具体享元规范需要实现的公共接口,非享元的外部状态以参数的形式通过方法传入。 - **具体享元(Concrete Flyweight)角色**:实现抽象享元角色中所规定的接口。 - **非享元(Unsharable Flyweight)角色**:是不可以共享的外部状态,它以参数的形式注入具体享元的相关方法中。 - **享元工厂(Flyweight Factory)角色**:负责创建和管理享元角色。当客户对象请求一个享元对象时,享元工厂检査系统中是否存在符合要求的享元对象,如果存在则提供给客户;如果不存在的话,则创建一个新的享元对象。 ### 三、源码中享元模式体现 #### 3.1 String中的享元模式 Java中将String类定义为final(不可改变的),JVM中字符串一般保存在字符串常量池中,Java会确保一个字符串在常量池中只有一个拷贝,这个字符串常量池在JDK6.0以前是位于常量池中,位于永久代带,而在JDK7.0中,JVM将其从永久带拿出来放置于堆中。 **示例** ```java public class StringTest { public static void main(String[] args) { // s1与s2的赋值皆为常量 String s1 = "hello"; String s2 = "hello"; // s3的赋值为常量,s4的赋值为常量加变量 String s3 = "he" + "llo"; String s4 = "hel" + new String("lo"); // s5的赋值为变量,s6的赋值为intern()方法 String s5 = new String("hello"); String s6 = s5.intern(); String s7 = "h"; String s8 = "ello"; String s9 = s7 + s8; System.out.println(s1==s2);//true System.out.println(s1==s3);//true System.out.println(s1==s4);//false System.out.println(s1==s9);//false System.out.println(s4==s5);//false System.out.println(s1==s6);//true } } ``` 在上面的代码示例中,由于String类的final修饰,以字面量的形式创建String变量时,JVM会在编译期间就把该字面量放入字符串常量池中。由Java程序启动的时候就已经加载到内存中了。如同上面的示例中的s1的“hello”赋值,“hello”便被放入了常量池中,而s6的赋值是通过intern()方法赋值,s5的内容为"hello",所以s6的值也是指向常量池。 #### 3.2 Integer中的享元模式 大家都非常熟悉的对象Integer,也用到了享元模式,看下方的示例: ```java /** * Created by lilinchao * Date 2022/11/12 * Description Integer中的享元模式 */ public class IntegerTest { public static void main(String[] args) { Integer a = Integer.valueOf(100); Integer b = 100; Integer c = Integer.valueOf(1000); Integer d = 1000; System.out.println("a==b:" + (a==b)); System.out.println("c==d:" + (c==d)); } } ``` **运行结果** ``` a==b:true c==d:false ``` 大家对这个结果是不是也感觉很诧异。之所以得倒这样的结果,是因为Integer用到的享元模式。 **来看Integer的源码** ```java public static Integer valueOf(int i) { if (i >= IntegerCache.low && i <= IntegerCache.high) return IntegerCache.cache[i + (-IntegerCache.low)]; return new Integer(i); } ``` Integer源码中的`valueOf()`方法做了一个条件判断,如果目标值在-128~127之间,则直接从缓存中取值,否则新建对象。 **那JDK为什么要这样呢?** 因为在-128~127之间的数据在int范围内是使用最频繁的,为了节省频繁创建对象带来的内存损耗,这里就用到了享元模式,来提高性能。 **注意** 除了Integer类型,JDK提供的包装类Boolean, Byte, Short, Long, Character也都进行了缓存。 + Byte, Short, Long 缓存的范围都是 -128~127 + Character 缓存的范围是 0~127 + Integer的默认范围是 -128~127,最小值不能变,但最大值可以通过调整虚拟机参数`"-Djava.lang.Integer.IntegerCache.high`" 来改变 + Boolean 缓存了 TRUE 和 FALSE 除了上述介绍的之外,`BigDecimal`和`BigInteger`也使用了享元模式。 ### 四、DIY (数据库连接池) **需求** > 一个线上商城应用,QPS 达到数千,如果每次都重新创建和关闭数据库连接,性能会受到极大影响。 这时预先创建好一批连接,放入连接池。一次请求到达后,从连接池获取连接,使用完毕后再还回连接池,这样既节约了连接的创建和关闭时间,也实现了连接的重用,不至于让庞大的连接数压垮数据库。 **代码实现** ```java //连接池实现类 class Pool { //定义连接池大小 private final int poolSize; //连接对象数组 private Connection[] connections; //定义连接状态数组 0:表示空闲,1:表示繁忙 private AtomicIntegerArray states; //构造方法初始化 public Pool(int poolSize) { this.poolSize = poolSize; this.connections = new Connection[poolSize]; this.states = new AtomicIntegerArray(new int[poolSize]); for (int i = 0; i < poolSize; i++) { connections[i] = new MockConnection("conn " + i); } } //借连接 public Connection borrow() { while (true) { //遍历连接状态数组,找出空闲的连接并返回 for (int i = 0; i < poolSize; i++) { if (states.get(i) == 0) { //为了先线程安全,需要使用CAS对连接状态进行设置 if (states.compareAndSet(i, 0, 1)) { System.out.println(Thread.currentThread().getName() + " borrow " + connections[i]); return connections[i]; } } } //当前没有连接池时,进入等待状态 synchronized (this) { try { System.out.println(Thread.currentThread().getName() + " wait..."); this.wait(); } catch (InterruptedException e) { e.printStackTrace(); } } } } //归还连接 public void free(Connection conn) { for (int i = 0; i < poolSize; i++) { if (connections[i] == conn) { //由于此时只有一个线程持有connections[i],所以不会有线程安全问题 states.set(i, 0); //归还之后,通知等待的线程 synchronized (this) { System.out.println(Thread.currentThread().getName() + " free " + conn); this.notifyAll(); } break; } } } } //连接实现类,无具体内容,省略 class MockConnection implements Connection { //... } ``` **测试代码** ```java public static void main(String[] args) { //创建2两个连接 Pool pool = new Pool(2); //创建5个线程使用链接 for (int i = 0; i < 5; i++) { new Thread(() -> { //创建连接 Connection conn = pool.borrow(); try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } finally { //释放连接 pool.free(conn); } }, "线程 " + i).start(); } } ``` **运行结果** ``` 线程 1 borrow MockConnection{name='conn 0'} 线程 0 borrow MockConnection{name='conn 1'} 线程 2 wait... 线程 3 wait... 线程 4 wait... 线程 1 free MockConnection{name='conn 0'} 线程 4 borrow MockConnection{name='conn 0'} 线程 3 wait... 线程 2 wait... 线程 0 free MockConnection{name='conn 1'} 线程 2 borrow MockConnection{name='conn 1'} 线程 3 wait... 线程 4 free MockConnection{name='conn 0'} 线程 3 borrow MockConnection{name='conn 0'} 线程 2 free MockConnection{name='conn 1'} 线程 3 free MockConnection{name='conn 0'} ``` **以上实现没有考虑**: + 连接的动态增长与收缩 + 连接保活(可用性检测) + 等待超时处理 + 分布式 hash 对于关系型数据库,有比较成熟的连接池实现,例如c3p0, druid等 对于更通用的对象池,可以考虑使用apache commons pool,例如redis连接池可以参考jedis中关于连接池的实现 ### 总结 + 享元模式运用共享技术有效地支持大量细粒度对象的复用。系统只使用少量的对象,而这些对象都很相似,状态变化很小,可以实现对象的多次复用,它是一种对象结构型模式。 + 享元模式包含四个角色: + 抽象享元类声明一个接口,通过它可以接受并作用于外部状态; + 具体享元类实现了抽象享元接口,其实例称为享元对象; + 非共享具体享元是不能被共享的抽象享元类的子类; + 享元工厂类用于创建并管理享元对象,它针对抽象享元类编程,将各种类型的具体享元对象存储在一个享元池中。 + 享元模式以共享的方式高效地支持大量的细粒度对象,享元对象能做到共享的关键是区分内部状态和外部状态。其中内部状态是存储在享元对象内部并且不会随环境改变而改变的状态,因此内部状态可以共享;外部状态是随环境改变而改变的、不可以共享的状态。 + 享元模式 + 优点在于它可以极大减少内存中对象的数量,使得相同对象或相似对象在内存中只保存一份; + 缺点是使得系统更加复杂,并且需要将享元对象的状态外部化,而读取外部状态使得运行时间变长。 + 享元模式适用情况包括: + 一个系统有大量相同或者相似的对象,由于这类对象的大量使用,造成内存的大量耗费; + 对象的大部分状态都可以外部化,可以将这些外部状态传入对象中; + 多次重复使用享元对象。 *附参考文章链接* *https://blog.csdn.net/Sharker_Blog/article/details/122053106* *https://www.cnblogs.com/wuqinglong/p/12402562.html*
标签:
并发编程
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://lilinchao.com/archives/2573.html
上一篇
39.并发编程之不可变类的设计与应用
下一篇
41.并发编程之final详解
评论已关闭
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
NLP
4
标签云
Livy
Hadoop
Nacos
JavaWeb
高并发
数据结构
pytorch
Shiro
机器学习
Java阻塞队列
NIO
JavaSE
查找
Map
LeetCode刷题
Kafka
Redis
MySQL
Python
Elastisearch
Git
JVM
ajax
Golang
稀疏数组
Flink
BurpSuite
FastDFS
Yarn
设计模式
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞
评论已关闭