李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
03.数仓建设之离线数仓建设实战
Leefs
2022-09-22 AM
1499℃
0条
[TOC] ### 前言 > 技术是为业务服务的,业务是为公司创造价值的,离开业务的技术是无意义的。 ### 一、业务介绍 需要针对不同需求的用户开发不同的产品,所以公司内部有很多条业务线,但是对于数据部门来说,所有业务线的数据都是数据源。对数据的划分不只是根据业务进行,而是结合数据的属性。 ### 二、早期规划 之前开发是不同业务线对应不同的数据团队,每个数据团队互不干扰,这种模式比较简单,只针对自己的业务线进行数仓建设及报表开发即可。 但是随着业务的发展,频繁迭代及跨部门的垂直业务单元越来越多,业务之间的出现耦合情况,这时再采用这种烟囱式开发就出现了问题: 例如权限问题,公司对数据管理比较严格,不同的数据开发组没有权限共享数据,需要其他业务线的数据权限需要上报审批,比较耽误时间; 还有重复开发问题,不同业务线会出现相同的报表需求,如果每个业务方都开发各自的报表,太浪费资源。 所以对于数据开发而言,需要对各个业务线的数据进行统一管理,所以就有了数据中台的出现。 ### 三、数据中台 我认为数据中台是根据每个公司具体的业务需求而搭建的,不同的业务,对中台的理解有所不同。 公司内部开发的敏捷数据中台,主要从数据技术和计算能力的复用,到数据资产和数据服务的复用,数据中台以更大价值带宽,快准精让数据直接赋能业务。提供一个统一化的管理,打破数据孤岛,追溯数据血缘,实现自助化及高复用度。 如下所示: 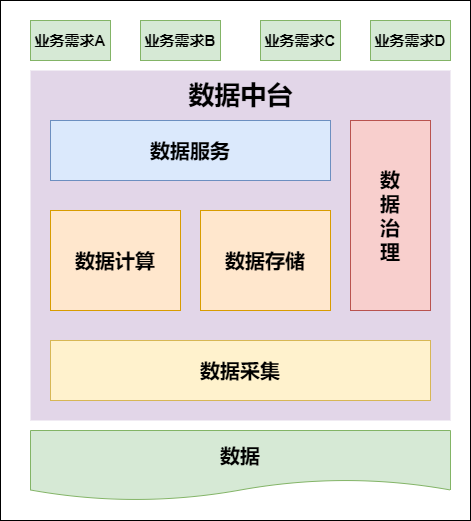 以上解释比较抽象,我们以实际项目开发来看下数据中台的便利性。 比如我们之前做报表开发流程,首先是要数据采集,不同的数据源通过sqoop等工具采集到大数据平台,然后进行数仓搭建,最后产出报表数据,放到可视化系统展示,最终把整个流程写成脚本放到调度平台进行自动化执行。 而有了数据中台之后就不需要那么繁琐,直接进行数仓搭建,产生报表即可,无需将精力过多放在数据源、可视化展示及调度。并且可以直观的查看数据血缘关系,计算表之间血缘。像下面图中,表之间的依赖关系很明确:  另一点,数据中台的异构数据系统可以非常简单的进行关联查询,比如hive的表关联MySQL的表。可透明屏蔽异构数据系统异构交互方式,轻松实现跨异构数据系统透明混算。 **异构数据系统原理是数据中台提供虚拟表到物理表之间的映射,终端用户无需关心数据的物理存放位置和底层数据源的特性,可直接操作数据,体验类似操作一个虚拟数据库**。 数据中台额外集成可视化展示,提供一站式数据可视化解决方案,支持JDBC数据源和CSV文件上传,支持基于数据模型拖拽智能生成可视化组件,大屏展示自适应不同大小屏幕。 调度系统是公司内部自写集成到数据中台的,在编写完sql语句之后可以直接进行调度。 ### 四、数仓建设 到这才真正到数仓建设,为什么前面我要占那么大篇幅去介绍公司业务及所使用的数据中台系统,因为下面的数仓建设是根据公司的业务发展及现有的数据中台进行,数仓的建设离不开公司的业务。 **数仓建设核心思想:从设计、开发、部署和使用层面,避免重复建设和指标冗余建设,从而保障数据口径的规范和统一,最终实现数据资产全链路关联、提供标准数据输出以及建立统一的数据公共层**。有了核心思想,那怎么开始数仓建设,有句话说数仓建设者即是技术专家,也是大半个业务专家,所以采用的方式就是需求推动数据建设,并且因为数据中台,所以各业务知识体系比较集中,各业务数据不再分散,加快了数仓建设速度。 数仓建设主要从两个方面进行,**模型和规范**,所有业务进行统一化。 **1)模型** 所有业务采用统一的模型体系,从而降低研发成本,增强指标复用,并且能保证数据口径的统一。 **2)模型分层** 结合公司业务,后期新增需求较多,所以分层不宜过多,并且需要清晰明确各层职责,要保证数据层的稳定又要屏蔽对下游影响,所以采用如下分层结构:  **3)数据流向** 遵循模型开发时分层结构,数据从 `ods -> dw -> dm ->app` 这样正向流动,可以防止因数据引用不规范而造成数据链路混乱及SLA时效难保障等问题,同时保证血缘关系简洁化,能够轻易追踪数据流向。在开发时应避免以下情况出现: - 数据引用链路不正确,如 `ods -> dm ->app` ,出现这种情况说明明细层没有完全覆盖数据;如 `ods -> dw -> app` ,说明轻度汇总层主题划分未覆盖全 。减少跨层引用,才能提高中间表的复用度。理想的数仓模型设计应当具备:数据模型可复⽤,完善且规范。 - 尽量避免一层的表生成当前层的表,如dw层表生成dw层表,这样会影响ETL效率。 - 禁止出现反向依赖,如dw表依赖于dm表。 **4)规范** **①表命名规范** - 对于ods、dm、app层表名:`类型_主题_表含义`,如:`dm_xxsh_user` - 对于dw层表名:`类型_主题_维度_表含义`,如:`dw_xxsh_fact_users`(事实表)、`dw_xxsh_dim_city`(维度表) **②字段命名规范** 构建词根,词根是维度和指标管理的基础,划分为普通词根与专有词根 - 普通词根:描述事物的最小单元体,如:sex-性别。 - 专有词根:具备行业专属或公司内部规定的描述体,如:xxsh-公司内部对某个产品的称呼。 **③脚本命名规范** 脚本名称:`脚本类型.脚本功用.[库名].脚本名称`,如 `hive.hive.dm.dm_xxsh_users` 脚本类型主要分为以下三类: - 常规Hive sql:hive - 自定义shell脚本:sh - 自定义Python脚本:python **④脚本内容规范** ```shell #变量的定义要符合python的语法要求 #指定任务负责人 owner = "zhangsan@xxx.com" #脚本存放目录/opt/xxx #脚本名称 hive.hive.dm.dm_xxsh_users #source用来标识上游依赖表,一个任务如果有多个上游表,都需要写进去 #(xxx_name 是需要改动的,其余不需要改) source = { "table_name": { "db": "db_name", "table": "table_name" } } #如source,但是每个任务target只有一张表 target = { "db_table": { "host": "hive", "db": "db_name", "table": "table_name" } } #变量列表 #$now #$now.date 常用,格式示例:2020-12-11 task = ''' 写sql代码 ''' ``` ### 五、数据层具体实现 使用四张图说明每层的具体实现: **1)数据源层ODS**  数据源层主要将各个业务数据导入到大数据平台,作为业务数据的快照存储。 **2)数据明细层DW**  事实表中的每行对应一个度量,每行中的数据是一个特定级别的细节数据,称为粒度。维度建模的核心原则之一是**同一事实表中的所有度量必须具有相同的粒度**。这样能确保不会出现重复计算度量的问题。 维度表一般都是单一主键,少数是联合主键,注意维度表不要出现重复数据,否则和事实表关联会出现**数据发散**问题。 有时候往往不能确定该列数据是事实属性还是维度属性。记住**最实用的事实就是数值类型和可加类事实**。所以可以通过分析该列是否是一种包含多个值并作为计算的参与者的度量,这种情况下该列往往是事实;如果该列是对具体值的描述,是一个文本或常量,某一约束和行标识的参与者,此时该属性往往是维度属性。但是还是要结合业务进行最终判断是维度还是事实。 **3)数据轻度汇总层DM**  此层命名为轻汇总层,就代表这一层已经开始对数据进行汇总,但是不是完全汇总,只是对相同粒度的数据进行关联汇总,不同粒度但是有关系的数据也可进行汇总,此时需要将粒度通过聚合等操作进行统一。 **4)数据应用层APP**  数据应用层的表就是提供给用户使用的,数仓建设到此就接近尾声了,接下来就根据不同的需求进行不同的取数,如直接进行报表展示,或提供给数据分析的同事所需的数据,或其他的业务支撑。 ### 六、总结 **一张图总结下数据仓库的构建整体流程**:  ### 七、实际生产中注意事项 生产环境中操作不能像我们自己测试时那样随意,一不小心都可能造成生产事故。所以每步操作都要十分小心,需全神贯注,管好大脑管住右手。 仅列出以下但不限于以下的注意事项: - 请勿操作自己管理及授权表之外的其它库表; - 未经授权,请勿操作生产环境中其他人的脚本及文件; - 在修改生产环境脚本前,请务必自行备份到本地; - 请确认自己的修改操作能迅速回滚; - 生产环境中表名及字段等所有命名请遵循命名规则。 *原文链接地址* *https://mp.weixin.qq.com/s/md49ODhLOOlqv8O_x41lsQ*
标签:
DataWarehouse
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://lilinchao.com/archives/2384.html
上一篇
02.数仓建设之离线数仓建设核心
下一篇
04.数仓建设之实时计算
评论已关闭
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
NLP
4
标签云
SpringCloud
字符串
MyBatis-Plus
RSA加解密
Beego
Elastisearch
随笔
Spark
FileBeat
并发编程
JavaWeb
锁
NIO
JVM
LeetCode刷题
Scala
并发线程
Zookeeper
Ubuntu
Spark SQL
Yarn
Sentinel
Azkaban
DataX
递归
SpringBoot
Spring
稀疏数组
Flink
Java阻塞队列
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞
评论已关闭