李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
27.【转载】Flink ProcessFunction API全解析及实战
Leefs
2022-01-29 PM
2107℃
0条
[TOC] ### 一、Process Function 我们之前学习的**转换算子**是无法访问**事件的时间戳信息和水位线信息**的,例如MapFunction这样的map转换算子就无法访问时间戳或者当前事件的事件时间。而这在一些应用场景下,极为重要。基于此,DataStream API提供了一系列的Low-Level转换算子,可以**访问时间戳、watermark以及注册定时事件**。还可以输出特定的一些事件,例如超时事件等。 Process Function用来构建事件驱动的应用以及实现自定义的业务逻辑,**Flink提供了8个Process** **Function:** + ProcessFunction + KeyedProcessFunction + CoProcessFunction + ProcessJoinFunction + BroadcastProcessFunction + KeyedBroadcastProcessFunction + ProcessWindowFunction + ProcessAllWindowFunction #### 1. ProcessFunction ProcessFunction是一个低阶的流处理操作,它可以访问流处理程序的基础构建模块:事件 Event,状态 State和定时器 Timers。 1. 对processElement函数的每次调用都获得一个Context对象,该对象可以访问元素的Event time,Timestamp和TimerService。 2. 通过RuntimeContext访问keyed state。 3. TimerService可用于为将来的event/process time瞬间注册回调。当到达计时器的特定时间时,将调用onTimer方法。在该调用期间,所有状态都再次限定在创建计时器时使用的键的范围内,从而允许计时器操作键控状态。 *PS:本文的学习模式是每介绍完一个Process Function的使用后,贴出入门的学习案例。* ```java package processfunction import org.apache.flink.api.common.functions.RichFlatMapFunction import org.apache.flink.streaming.api.functions.ProcessFunction import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment import org.apache.flink.util.Collector import org.apache.flink.streaming.api.scala._ /** * @Author Natasha * @Description * @Date 2020/11/4 16:40 **/ object ProcessFunctionDemo { val WORDS = "To be, or not to be,--that is the question:--" def main(args: Array[String]): Unit = { val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment env.setParallelism(1) env.fromElements(WORDS) .flatMap(new RichFlatMapFunction1) .process(new ProcessFunction1) .print() env.execute() } class ProcessFunction1 extends ProcessFunction[(String, Integer), (String, Integer)] { override def processElement(value: (String, Integer), ctx: ProcessFunction[(String, Integer), (String, Integer)]#Context, out: Collector[(String, Integer)]): Unit = { out.collect(value._1, value._2 + 1) } } class RichFlatMapFunction1 extends RichFlatMapFunction[String, (String, Integer)] { override def flatMap(value: String, collector: Collector[(String, Integer)]): Unit = { val spliters = value.toLowerCase.split("\\W+") // \\W+ 匹配0到多个字符 for (v <- spliters) { if (v.length > 0) { collector.collect((v, 1)) } } } } } ``` #### 2.KeyedProcessFunction KeyedProcessFunction作为ProcessFunction的扩展,在其onTimer方法中提供对定时器对应key的访问。 KeyedProcessFunction 用来处理 KeyedStream流,KeyedProcessFunction [KEY, IN, OUT] 还额外提供了两个方法: + `processElement(in: IN, ctx: Context, out: Collector[OUT])`, 流中的每一个元素都会调用这个方法,调用结果将会放在 Collector 数据类型中输出。Context可以访问元素的时间戳,元素的 key,以及 TimerService 时间服务。Context还可以将结果输出到别的流(side outputs)。 + `onTimer(timestamp: Long, ctx: OnTimerContext, out: Collector[OUT])`是一个回调函数,当之前注册的定时器触发时被调用。参数 timestamp 是定时器设置的触发时间戳,Collector 是结果集合,OnTimerContext 和提供了上下文的一些信息,例如定时器触发的时间信息(事件时间或者处理时间)。 ```java package processfunction import org.apache.flink.api.common.functions.RichFlatMapFunction import org.apache.flink.streaming.api.functions.KeyedProcessFunction import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment import org.apache.flink.streaming.api.scala._ import org.apache.flink.util.Collector /** * @Author Natasha * @Description * @Date 2020/11/4 15:45 **/ object KeyedProcessFunctionDemo { val WORDS = "To be, or not to be,--that is the question:--" def main(args: Array[String]): Unit = { val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment env.setParallelism(1) env.fromElements(WORDS) .flatMap(new RichFlatMapFunction1) .keyBy(_._1) .process(new KeyedProcessFunction1) .print() env.execute() } class KeyedProcessFunction1 extends KeyedProcessFunction[String, (String, Integer), (String, Integer)] { override def processElement(value: (String, Integer), ctx: KeyedProcessFunction[String, (String, Integer), (String, Integer)]#Context, out: Collector[(String, Integer)]): Unit = { //用于KeyedStream,keyBy之后的流处理,故可以拿到ctx.getCurrentKey out.collect(ctx.getCurrentKey + ")" + value._1, value._2 + 1) } } class RichFlatMapFunction1 extends RichFlatMapFunction[String, (String, Integer)] { override def flatMap(value: String, collector: Collector[(String, Integer)]): Unit = { val spliters = value.toLowerCase.split("\\W+") for (v <- spliters) { if (v.length > 0) { collector.collect((v, 1)) } } } } } ``` #### 3.ProcessWindowFunction `ProcessWindowFunction`要对窗口内的全量数据都缓存,使用时,Flink将某个Key下某个窗口的所有元素都缓存在`Iterable<IN>`中,我们需要对其进行处理使用`Collector<OUT>`收集输出。我们可以使用`Context`获取窗口内更多的信息,包括时间、状态、迟到数据发送位置等。 下面的代码是一个`ProcessWindowFunctionDemo`的简单应用,我们对价格出现的次数做了统计,选出出现次数最多的输出出来。 ```java package windowfunction import model.StockPrice import org.apache.flink.streaming.api.TimeCharacteristic import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment import org.apache.flink.streaming.api.scala._ import org.apache.flink.streaming.api.scala.function.ProcessWindowFunction import org.apache.flink.streaming.api.windowing.time.Time import org.apache.flink.streaming.api.windowing.windows.TimeWindow import org.apache.flink.util.Collector /** * @Author Natasha * @Description * @Date 2020/11/18 15:57 **/ object ProcessWindowFunctionDemo { def main(args: Array[String]): Unit = { val aenv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment aenv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) aenv.setParallelism(1) val resource = getClass.getResource("/AggregateFunctionLog.csv").getPath val socketStream = aenv.readTextFile(resource) val input = socketStream .map(data => { val arr = data.split(",") StockPrice(arr(0), arr(1).toDouble, arr(2).toLong) }) .assignAscendingTimestamps(_.timestamp * 1000L) val frequency = input .keyBy(s => s.symbol) .timeWindow(Time.seconds(10)) .process(new ProcessWindowFunction1) .print() aenv.execute() } class ProcessWindowFunction1 extends ProcessWindowFunction[StockPrice, (String, Double), String, TimeWindow] { override def process(key: String, context: Context, elements: Iterable[StockPrice], out: Collector[(String, Double)]): Unit = { // 股票价格和该价格出现的次数 var countMap = scala.collection.mutable.Map[Double, Int]() for(element <- elements) { val count = countMap.getOrElse(element.price, 0) countMap(element.price) = count + 1 } // 按照出现次数从高到低排序 val sortedMap = countMap.toSeq.sortWith(_._2 > _._2) // 选出出现次数最高的输出到Collector if (sortedMap.size > 0) { out.collect((key, sortedMap(0)._1)) } } } } ``` ### 二、在两个DataStream上进行Join操作 #### 4.JoinFunction **基于窗口的Join**需要用到Flink的窗口机制,其原理是将两条输入流中的元素分配到公共窗口中并进行窗口完成时进行的Join(或coGroup) ```java input1.join(input2) .where(<KeySelector>) <- input1使用哪个字段作为Key .equalTo(<KeySelector>) <- input2使用哪个字段作为Key .window(<WindowAssigner>) <- 指定WindowAssigner [.trigger(<Trigger>)] <- 指定Trigger(可选) [.evictor(<Evictor>)] <- 指定Evictor(可选) .apply(<JoinFunction>) <- 指定JoinFunction ``` 下图展示了Join的大致过程:两个输入数据流input1和input2分别按Key进行分组,元素使用`WindowAssigner`划分到窗口中,这里可以使用Flink提供的滚动窗口、滑动窗口或会话窗口等默认的`WindowAssigner`。随后两个数据流中的元素会被分配到各个窗口上,也就是说一个窗口会包含来自两个数据流的元素。 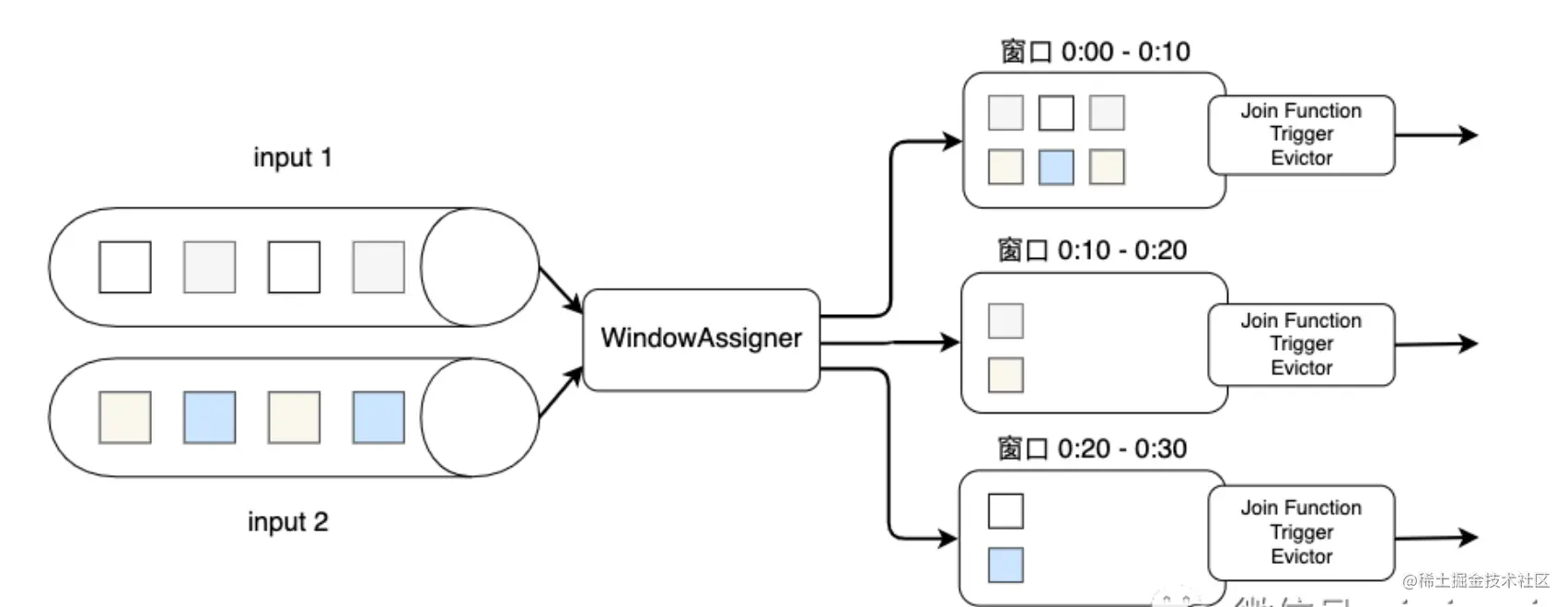 相同窗口内的数据会以INNER JOIN的语义来相互关联,形成一个数据对,即数据源input1中的某个元素与数据源input2中的所有元素逐个配对。当窗口的时间结束,Flink会调用`JoinFunction`来对窗口内的数据对进行处理。  ```java package processfunction import org.apache.flink.api.common.functions.JoinFunction import org.apache.flink.streaming.api.TimeCharacteristic import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows import org.apache.flink.streaming.api.windowing.time.Time import org.apache.flink.streaming.api.scala._ /** * @Author Natasha * @Description * @Date 2020/11/19 14:20 **/ object JoinFunctionDemo { def main(args: Array[String]): Unit = { val env = StreamExecutionEnvironment.getExecutionEnvironment env.setParallelism(1) env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) val orangeStream = env .fromElements( (1, 1999L), (1, 2001L)) .assignAscendingTimestamps(_._2) val greenStream = env .fromElements( (1, 1001L), (1, 1002L), (1, 3999L)) .assignAscendingTimestamps(_._2) orangeStream.join(greenStream) .where(r => r._1) .equalTo(r => r._1) .window(TumblingEventTimeWindows.of(Time.seconds(2))) // .apply { (e1, e2) => e1 + " *** " + e2 .apply(new MyJoinFunction) .print() env.execute() } class MyJoinFunction extends JoinFunction[(Int, Long), (Int, Long), String] { override def join(input1: (Int, Long), input2: (Int, Long)): String = { input1 + " *** " + input2 } } } ``` #### 5.CoGroupFunction 如果INNER JOIN不能满足我们的需求,`CoGroupFunction`提供了更多可自定义的功能。需要注意的是,在调用时,要写成`input1.coGroup(input2).where(<KeySelector>).equalTo(<KeySelecotr>)`。 ```java input1.coGroup(input2) .where(<KeySelector>) <- input1使用哪个字段作为Key .equalTo(<KeySelector>) <- input2使用哪个字段作为Key .window(<WindowAssigner>) <- 指定WindowAssigner [.trigger(<Trigger>)] <- 指定Trigger(可选) [.evictor(<Evictor>)] <- 指定Evictor(可选) .apply(<CoGroupFunction>) <- CoGroupFunction ``` ```java package processfunction import java.text.SimpleDateFormat import model.{StockSnapshot, StockTransaction} import org.apache.flink.api.common.functions.CoGroupFunction import org.apache.flink.streaming.api.TimeCharacteristic import org.apache.flink.streaming.api.scala._ import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows import org.apache.flink.streaming.api.windowing.time.Time import org.apache.flink.util.Collector /** * @Author Natasha * @Description * @Date 2020/11/19 15:01 * @data * Transaction: * 2016-07-28 13:00:01.820,000001,10.2 * 2016-07-28 13:00:01.260,000001,10.2 * 2016-07-28 13:00:02.980,000001,10.1 * 2016-07-28 13:00:03.120,000001,10.1 * 2016-07-28 13:00:04.330,000001,10.0 * 2016-07-28 13:00:05.570,000001,10.0 * 2016-07-28 13:00:05.990,000001,10.0 * 2016-07-28 13:00:14.000,000001,10.1 * 2016-07-28 13:00:20.000,000001,10.2 * Snapshot: * 2016-07-28 13:00:01.000,000001,10.2 * 2016-07-28 13:00:04.000,000001,10.1 * 2016-07-28 13:00:07.000,000001,10.0 * 2016-07-28 13:00:16.000,000001,10.1 **/ object CoGroupFunctionDemo { val format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS") def main(args : Array[String]) : Unit ={ val env = StreamExecutionEnvironment.getExecutionEnvironment env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) val dataStream1 = env.socketTextStream("localhost", 8998) val dataStream2 = env.socketTextStream("localhost", 8999) /** * operator操作 * 数据格式如下: * TX:2016-07-28 13:00:01.000,000002,10.2 * MD: 2016-07-28 13:00:00.000,000002,10.1 * 这里由于是测试,固水位线采用升序(即数据的Event Time本身是升序输入的) */ val dataStreamMap1 = dataStream1 .map(f => { val tokens1 = f.split(",") StockTransaction(tokens1(0), tokens1(1), tokens1(2).toDouble) }) .assignAscendingTimestamps(f => format.parse(f.tx_time).getTime) val dataStreamMap2 = dataStream2 .map(f => { val tokens2 = f.split(",") StockSnapshot(tokens2(0), tokens2(1), tokens2(2).toDouble) }) .assignAscendingTimestamps(f => format.parse(f.md_time).getTime) val joinedStream = dataStreamMap1 .coGroup(dataStreamMap2) .where(_.tx_code) .equalTo(_.md_code) .window(TumblingEventTimeWindows.of(Time.seconds(3))) val innerJoinedStream = joinedStream.apply(new InnerJoinFunction) val leftJoinedStream = joinedStream.apply(new LeftJoinFunction) val rightJoinedStream = joinedStream.apply(new RightJoinFunction) innerJoinedStream.name("InnerJoinedStream").print() leftJoinedStream.name("LeftJoinedStream").print() rightJoinedStream.name("RightJoinedStream").print() env.execute("3 Type of Double Stream Join") } class InnerJoinFunction extends CoGroupFunction[StockTransaction,StockSnapshot,(String,String,String,Double,Double,String)]{ override def coGroup(T1: java.lang.Iterable[StockTransaction], T2: java.lang.Iterable[StockSnapshot], out: Collector[(String, String, String, Double, Double,String)]): Unit = { /** * 将Java中的Iterable对象转换为Scala的Iterable * scala的集合操作效率高,简洁 */ import scala.collection.JavaConverters._ val scalaT1 = T1.asScala.toList val scalaT2 = T2.asScala.toList /** * Inner Join要比较的是同一个key下,同一个时间窗口内的数据 */ if(scalaT1.nonEmpty && scalaT2.nonEmpty){ for(transaction <- scalaT1){ for(snapshot <- scalaT2){ out.collect(transaction.tx_code,transaction.tx_time, snapshot.md_time,transaction.tx_value,snapshot.md_value,"Inner Join Test") } } } } } class LeftJoinFunction extends CoGroupFunction[StockTransaction,StockSnapshot,(String,String,String,Double,Double,String)] { override def coGroup(T1: java.lang.Iterable[StockTransaction], T2: java.lang.Iterable[StockSnapshot], out: Collector[(String, String, String, Double,Double,String)]): Unit = { /** * 将Java中的Iterable对象转换为Scala的Iterable * scala的集合操作效率高,简洁 */ import scala.collection.JavaConverters._ val scalaT1 = T1.asScala.toList val scalaT2 = T2.asScala.toList /** * Left Join要比较的是同一个key下,同一个时间窗口内的数据 */ if(scalaT1.nonEmpty && scalaT2.isEmpty){ for(transaction <- scalaT1){ out.collect(transaction.tx_code,transaction.tx_time, "",transaction.tx_value,0,"Left Join Test") } } } } class RightJoinFunction extends CoGroupFunction[StockTransaction,StockSnapshot,(String,String,String,Double,Double,String)] { override def coGroup(T1: java.lang.Iterable[StockTransaction], T2: java.lang.Iterable[StockSnapshot], out: Collector[(String, String, String, Double,Double,String)]): Unit = { /** * 将Java中的Iterable对象转换为Scala的Iterable * scala的集合操作效率高,简洁 */ import scala.collection.JavaConverters._ val scalaT1 = T1.asScala.toList val scalaT2 = T2.asScala.toList /** * Right Join要比较的是同一个key下,同一个时间窗口内的数据 */ if(scalaT1.isEmpty && scalaT2.nonEmpty){ for(snapshot <- scalaT2){ out.collect(snapshot.md_code, "",snapshot.md_time,0,snapshot.md_value,"Right Join Test") } } } } } ``` #### 6.ProcessJoinFunction **基于时间的双流Join**:与Window Join不同,Interval Join不依赖Flink的`WindowAssigner`,而是根据时间间隔(Interval)来界定时间。 ```java input1.intervalJoin(input2) .where(<KeySelector>) <- input1使用哪个字段作为Key .equalTo(<KeySelector>) <- input2使用哪个字段作为Key .window(<WindowAssigner>) <- 指定WindowAssigner [.trigger(<Trigger>)] <- 指定Trigger(可选) [.evictor(<Evictor>)] <- 指定Evictor(可选) .process(<ProcessJoinFunction>) <- 指定ProcessJoinFunction ``` Interval需要一个时间下界(lower bound)和上界(upper bound),如果我们将input1和input2进行Interval Join,input1中的某个元素为`input1.element1`,时间戳为`input1.element1.ts`,那么Interval就是`[input1.element1.ts + lower bound, input1.element1.ts + upper bound]`,input2中落在这个时间段内的元素将会和input1.element1组成一个数据对。 数学公式表达:`input1.element1.ts + lower bound <= input2.elementx.ts <=input1.element1.ts + upper bound`,上下界可以是正数也可以是负数。  ```java package processfunction import model.{UserBrowseLog, UserClickLog} import org.apache.flink.streaming.api.TimeCharacteristic import org.apache.flink.streaming.api.functions.co.ProcessJoinFunction import org.apache.flink.streaming.api.scala._ import org.apache.flink.streaming.api.windowing.time.Time import org.apache.flink.util.Collector /** * @Author Natasha * @Description * @Date 2020/11/19 13:51 **/ object ProcessJoinFunctionDemo { def main(args: Array[String]): Unit = { val env = StreamExecutionEnvironment.getExecutionEnvironment env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) env.setParallelism(1) val clickStream = env .fromElements( UserClickLog("user_2", "1500", "click", "page_1"), // (900, 1500) UserClickLog("user_2", "2000", "click", "page_1") // (1400, 2000) ) .assignAscendingTimestamps(_.eventTime.toLong * 1000L) .keyBy(_.userID) val browseStream = env .fromElements( UserBrowseLog("user_2", "1000", "browse", "product_1", "10"), // (1000, 1600) UserBrowseLog("user_2", "1500", "browse", "product_1", "10"), // (1500, 2100) UserBrowseLog("user_2", "1501", "browse", "product_1", "10"), // (1501, 2101) UserBrowseLog("user_2", "1502", "browse", "product_1", "10") // (1502, 2102) ) .assignAscendingTimestamps(_.eventTime.toLong * 1000L) .keyBy(_.userID) /** * 实现双流join */ clickStream.intervalJoin(browseStream) .between(Time.minutes(-10), Time.seconds(0)) //定义上下界为(-10,0) .process(new MyIntervalJoin) .print() env.execute() } class MyIntervalJoin extends ProcessJoinFunction[UserClickLog, UserBrowseLog, String] { override def processElement(left: UserClickLog, right: UserBrowseLog, ctx: ProcessJoinFunction[UserClickLog, UserBrowseLog, String]#Context, out: Collector[String]): Unit = { out.collect(left + " ==> " + right) } } } ``` ##### 总结 1. Windows类型的join都是利用window的机制,先将数据缓存在Window State中,当窗口触发时,执行join操作。 2. Interval join利用state存储数据再处理,区别在于state中的数据有失效机制,依靠数据触发数据清除。 #### 7.CoProcessFunction **使用connect和coProcessFunction实现双流join**:CoProcessFunction实现对两个输入的低阶操作,它绑定到两个不同的输入流,分别调用processElement1和processElement2对两个输入流的数据进行处理。 ```java input1.connect(input2) .where(<KeySelector>) <- input1使用哪个字段作为Key .equalTo(<KeySelector>) <- input2使用哪个字段作为Key .window(<WindowAssigner>) <- 指定WindowAssigner [.trigger(<Trigger>)] <- 指定Trigger(可选) [.evictor(<Evictor>)] <- 指定Evictor(可选) .process(<CoProcessFunction>) <- CoProcessFunction ``` 实现低阶join通常遵循: 1. 为一个(或两个)输入创建一个状态对象。 2. 当从输入源收到元素时,更新状态。 3. 从另一个输入接收元素后,检索状态并生成连接的结果。  ```java package processfunction import model.SensorReading import org.apache.flink.api.scala._ import org.apache.flink.api.common.state.{ValueState, ValueStateDescriptor} import org.apache.flink.api.scala.typeutils.Types import org.apache.flink.streaming.api.TimeCharacteristic import org.apache.flink.streaming.api.functions.co.CoProcessFunction import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment} import org.apache.flink.util.Collector import source.SensorSource /** * @Author Natasha * @Description * @Date 2020/11/19 16:13 **/ object CoProcessFunctionDemo { def main(args: Array[String]) { val env = StreamExecutionEnvironment.getExecutionEnvironment env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime) env.setParallelism(1) val filterSwitches: DataStream[(String, Long)] = env .fromCollection(Seq( ("sensor_2", 10 * 1000L), // forward readings of sensor_2 for 10 seconds ("sensor_7", 60 * 1000L)) // forward readings of sensor_7 for 1 minute) ) val readings: DataStream[SensorReading] = env .addSource(new SensorSource) val forwardedReadings = readings .connect(filterSwitches) .keyBy(_.id, _._1) .process(new ReadingFilter) .print() env.execute("Monitor sensor temperatures.") } class ReadingFilter extends CoProcessFunction[SensorReading, (String, Long), SensorReading] { // switch to enable forwarding lazy val forwardingEnabled: ValueState[Boolean] = getRuntimeContext.getState(new ValueStateDescriptor[Boolean]("filterSwitch", Types.of[Boolean])) // hold timestamp of currently active disable timer lazy val disableTimer: ValueState[Long] = getRuntimeContext.getState(new ValueStateDescriptor[Long]("timer", Types.of[Long])) override def processElement1( reading: SensorReading, ctx: CoProcessFunction[SensorReading, (String, Long), SensorReading]#Context, out: Collector[SensorReading]): Unit = { // check if we may forward the reading if (forwardingEnabled.value()) { out.collect(reading) } } override def processElement2( switch: (String, Long), ctx: CoProcessFunction[SensorReading, (String, Long), SensorReading]#Context, out: Collector[SensorReading]): Unit = { // enable reading forwarding forwardingEnabled.update(true) // set disable forward timer val timerTimestamp = ctx.timerService().currentProcessingTime() + switch._2 val curTimerTimestamp = disableTimer.value() if (timerTimestamp > curTimerTimestamp) { // remove current timer and register new timer ctx.timerService().deleteProcessingTimeTimer(curTimerTimestamp) ctx.timerService().registerProcessingTimeTimer(timerTimestamp) disableTimer.update(timerTimestamp) } } override def onTimer( ts: Long, ctx: CoProcessFunction[SensorReading, (String, Long), SensorReading]#OnTimerContext, out: Collector[SensorReading]): Unit = { // remove all state. Forward switch will be false by default. forwardingEnabled.clear() disableTimer.clear() } } } ``` #### 8.KeyedCoProcessFunction 将五分钟之内的订单信息和支付信息进行对账,对不上的发出警告: ```java package processfunction import model.{OrderEvent, PayEvent} import org.apache.flink.api.common.state.{ValueState, ValueStateDescriptor} import org.apache.flink.api.scala.typeutils.Types import org.apache.flink.streaming.api.TimeCharacteristic import org.apache.flink.streaming.api.functions.co.KeyedCoProcessFunction import org.apache.flink.streaming.api.scala._ import org.apache.flink.util.Collector /** * @Author Natasha * @Description * @Date 2020/11/19 15:09 **/ object KeyedCoProcessFunctionDemo { // 用来输出没有匹配到的订单支付事件 val unmatchedOrders = new OutputTag[String]("unmatched-orders") // 用来输出没有匹配到的第三方支付事件 val unmatchedPays = new OutputTag[String]("unmatched-pays") def main(args: Array[String]): Unit = { val env = StreamExecutionEnvironment.getExecutionEnvironment env.setParallelism(1) env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) val orders = env .fromElements( OrderEvent("order_1", "pay", 2000L), OrderEvent("order_2", "pay", 5000L), OrderEvent("order_3", "pay", 6000L) ) .assignAscendingTimestamps(_.eventTime) .keyBy(_.orderId) val pays = env .fromElements( PayEvent("order_1", "weixin", 7000L), PayEvent("order_2", "weixin", 8000L), PayEvent("order_4", "weixin", 9000L) ) .assignAscendingTimestamps(_.eventTime) .keyBy(_.orderId) val processed = orders .connect(pays) .process(new MatchFunction) processed.getSideOutput(unmatchedOrders).print() processed.getSideOutput(unmatchedPays).print() processed.print() env.execute() } //进入同一条流中的数据肯定是同一个key,即OrderId class MatchFunction extends KeyedCoProcessFunction[String, OrderEvent, PayEvent, String] { lazy private val orderState: ValueState[OrderEvent] = getRuntimeContext.getState(new ValueStateDescriptor[OrderEvent]("orderState", Types.of[OrderEvent])) lazy private val payState: ValueState[PayEvent] = getRuntimeContext.getState(new ValueStateDescriptor[PayEvent]("payState", Types.of[PayEvent])) override def processElement1(value: OrderEvent, ctx: KeyedCoProcessFunction[String, OrderEvent, PayEvent, String]#Context, out: Collector[String]): Unit = { //从payState中查找数据,如果存在,说明匹配成功 val pay = payState.value() if (pay != null) { payState.clear() out.collect("订单ID为 " + pay.orderId + " 的两条流对账成功!") } else { //如果不存在,则说明可能对应的pay数据没有来,需要存入状态等待 //定义一个5min的定时器,到时候再匹配,如果还没匹配上,则说明匹配失败发出警告 orderState.update(value) ctx.timerService().registerEventTimeTimer(value.eventTime + 5000) } } override def processElement2(value: PayEvent, ctx: KeyedCoProcessFunction[String, OrderEvent, PayEvent, String]#Context, out: Collector[String]): Unit = { val order = orderState.value() if (order != null) { orderState.clear() out.collect("订单ID为 " + order.orderId + " 的两条流对账成功!") } else { payState.update(value) ctx.timerService().registerEventTimeTimer(value.eventTime + 5000) } } override def onTimer(timestamp: Long, ctx: KeyedCoProcessFunction[String, OrderEvent, PayEvent, String]#OnTimerContext, out: Collector[String]): Unit = { if (orderState.value() != null) { //将警告信息发送到侧输出流中 ctx.output(unmatchedOrders, s"订单ID为 ${orderState.value().orderId} 的两条流没有对账成功!") orderState.clear() } if (payState.value() != null) { ctx.output(unmatchedPays, s"订单ID为 ${payState.value().orderId} 的两条流没有对账成功!") payState.clear() } } } } ``` *附原文链接地址:* *https://juejin.cn/post/6897023672171626504*
标签:
Flink
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://lilinchao.com/archives/1884.html
上一篇
26.Flink状态编程操作示例
下一篇
28.Flink ProcessFunction应用示例
评论已关闭
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
NLP
4
标签云
Ubuntu
Kafka
JavaWeb
Linux
pytorch
MyBatis-Plus
Livy
Netty
正则表达式
Jenkins
机器学习
Java工具类
JavaSE
Map
Python
高并发
Hadoop
微服务
SpringCloudAlibaba
散列
人工智能
SpringBoot
并发线程
Elastisearch
nginx
Quartz
序列化和反序列化
JVM
栈
Beego
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞
评论已关闭