李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
08.Kafka生产者数据可靠性保证
Leefs
2021-09-23 AM
1295℃
0条
[TOC] ### 一、数据可靠性保证 为保证 producer 发送的数据,能可靠的发送到指定的 topic,topic 的每个 partition 收到 producer 发送的数据后,都需要向producer发送 ack(acknowledgement 确认收到),如果 producer 收到 ack,就会进行下一轮的发送,否则重新发送数据。 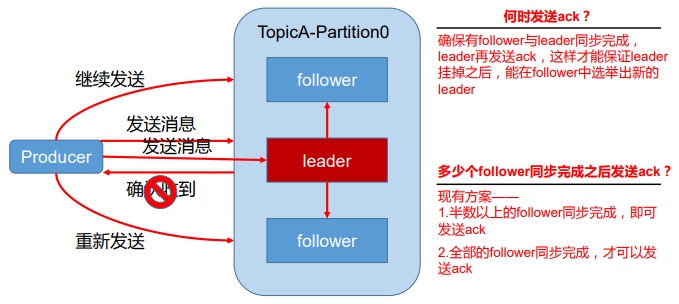 #### 1.1 副本数据同步策略 | 方案 | 优点 | 缺点 | | ----------------------------- | --------------------------------------------------- | ---------------------------------------------------------- | | 半数以上完成同步,就发 送 ack | 延迟低 | 选举新的 leader 时,容忍 n 台 节点的故障,需要 2n+1 个副本 | | 全部完成同步,才发送 ack | 选举新的leader 时,容忍n台节点的故障,需要n+1个副本 | 延迟高 | **Kafka 选择了第二种方案,原因如下:** + 同样为了容忍n台节点的故障,第一种方案需要 2n+1个副本,而第二种方案只需要n+1个副本,而Kafka的每个分区都有大量的数据,第一种方案会造成大量数据的冗余。 + 虽然第二种方案的网络延迟会比较高,但网络延迟对Kafka 的影响较小。 #### 1.2 ISR **采用第二种方案之后,设想以下情景:** leader 收到数据,所有 follower 都开始同步数据, 但有一个 follower,因为某种故障,迟迟不能与 leader 进行同步,那 leader 就要一直等下去, 直到它完成同步,才能发送 ack。 **这个问题怎么解决呢?** Leader 维护了一个动态的 in-sync replica set (ISR),意为和 leader保持同步的 follower 集合。 + 当 ISR 中的 follower 完成数据的同步之后,leader就会给 follower发送ack。 + 如果follower长时间未向leader同步数据 ,则该follower将被踢出ISR ,该时间阈值由replica.lag.time.max.ms 参数设定。 + Leader发生故障之后,就会从ISR中选举新的leader。 #### 1.3 ack应答机制 对于某些不太重要的数据,对数据的可靠性要求不是很高,能够容忍数据的少量丢失, 所以没必要等 ISR中的follower全部接收成功。 所以 Kafka 为用户提供了三种可靠性级别,用户根据对可靠性和延迟的要求进行权衡, 选择以下的配置。 **acks参数配置:** + **0:**producer不等待broker的ack,这一操作提供了一个最低的延迟,broker一接收到还没有写入磁盘就已经返回,当broker故障时有可能丢失数据; + **1:**producer等待broker的ack,partition的leader落盘成功后返回ack,如果在follower同步成功之前leader故障,那么将会丢失数据;  + **-1(all):**producer等待broker的ack,partition的leader和follower全部落盘成功后才返回 ack。但是如果在follower同步完成后,broker发送ack之前,leader发生故障,那么会造成数据重复。  #### 1.4 故障处理细节  + **LEO:**指的是每个副本最大的offset; + **HW:**指的是消费者能见到的最大的offset,ISR队列中最小的LEO。 **(1)follower故障** follower 故障后会被临时踢出ISR,待该 follower恢复后,follower会读取本地磁盘记录的上次的 HW,并将 log 文件高于HW 的部分截取掉,从HW开始向leader进行同步。 等该follower的LEO大于等于该Partition的HW,即follower追上leader之后,就可以重新加入ISR 了。 **(2)leader故障** leader发生故障之后,会从ISR中选出一个新的leader,之后,为保证多个副本之间的数据一致性,其余的follower会先将各自的log文件高于HW的部分截掉,然后从新的leader同步数据。 **注意:这只能保证副本之间的数据一致性,并不能保证数据不丢失或者不重复。** ### 二、Exactly Once语义 #### 2.1 三种语义 **(1)at-least-once:至少一次** 这种方式是在消费数据之后,手动调用函数`consumer.commitSync()`异步提交offset,有可能处理多次的场景是消费者的消息处理完并输出到结果库,但是offset还没提交,这个时候消费者挂掉了,再重启的时候会重新消费并处理消息,所以至少会处理一次 **注意:这种语义有可能会对数据重复处理** **配置** + 设置`enable.auto.commit`为false,禁用自动提交offset; + 消息处理完之后手动调用`consumer.commitSync()`提交offset。 **(2)at-most-once:至多一次**(默认) 消费者的offset已经提交,但是消息还在处理中(还没有处理完),这个时候程序挂了,导致数据没有被成功处理,再重启的时候会从上次提交的offset处消费,导致上次没有被成功处理的消息就丢失了。 **注意:这种语义有可能会丢失数据** **配置** + `enable.auto.commit`设置为true; + `auto.commit.interval.ms`设置为一个较低的时间范围。 由于上面的配置,此时kafka会有一个独立的线程负责按照指定间隔提交offset。 **(3)exactly-once:仅一次** 以原子事务的方式保存offset和处理的消息结果,这个时候相当于自己保存offset信息了,把offset和具体的数据绑定到一块,数据真正处理成功的时候才会保存offset信息。 **注意:这种语义可以保证数据只被消费处理一次。** **配置** + 将enable.auto.commit设置为false,禁用自动提交offset; + 使用consumer.seek(topicPartition,offset)来指定offset; + 在处理消息的时候,要同时保存住每个消息的offset。 #### 2.2 Exactly Once语义详解 Exactly Once语义目标:要求数据既不重复也不丢失。 在 0.11 版 本以前的 Kafka,对此是无能为力的,只能保证数据不丢失,再在下游消费者对数据做全局 去重。对于多个下游应用的情况,每个都需要单独做全局去重,这就对性能造成了很大影响。 0.11 版本的 Kafka,引入了一项重大特性:幂等性。所谓的幂等性就是指 Producer 不论 向 Server 发送多少次重复数据,Server 端都只会持久化一条。幂等性结合 At Least Once 语 义,就构成了 Kafka 的 Exactly Once 语义。即: > At Least Once + 幂等性 = Exactly Once 要启用幂等性,只需要将 Producer 的参数中 enable.idompotence 设置为 true 即可。 Kafka 的幂等性实现其实就是将原来下游需要做的去重放在了数据上游。 开启幂等性的 Producer 在初始化的时候会被分配一个 PID,发往同一 Partition 的消息会附带 Sequence Number。 而 Broker端会对做缓存,当具有相同主键的消息提交时,Broker 只会持久化一条。 但是 PID 重启就会变化,同时不同的 Partition 也具有不同主键,所以幂等性无法保证跨分区跨会话的 Exactly Once。 *附:* *文章来源《尚硅谷大数据之Kafka》*
标签:
Kafka
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://lilinchao.com/archives/1521.html
上一篇
中秋随笔
下一篇
09.Kafka消费过程分析
评论已关闭
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
NLP
4
标签云
DataX
持有对象
Scala
Flume
Kibana
Netty
HDFS
国产数据库改造
Typora
锁
Elastisearch
数学
Azkaban
机器学习
RSA加解密
容器深入研究
SpringCloudAlibaba
JVM
微服务
pytorch
SQL练习题
Spark
线程池
并发线程
JavaWeb
MyBatisX
CentOS
Redis
算法
Hadoop
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞
评论已关闭