李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
07.Kafka生产者分区策略
Leefs
2021-09-21 PM
2320℃
0条
[TOC] ### 前言 查阅了一些资料和看了许多网上的文章,总觉得没有把Kafka生产者分区策略给讲明白,本篇将围绕以下问题步步深入来对文章进行展开。 + 为什么需要生产者分区策略 + 生产者分区策略有哪些 + 不同分区策略有哪些优点和缺点 + 如何进行自定义分区策略 ### 一、生产者发送消息流程 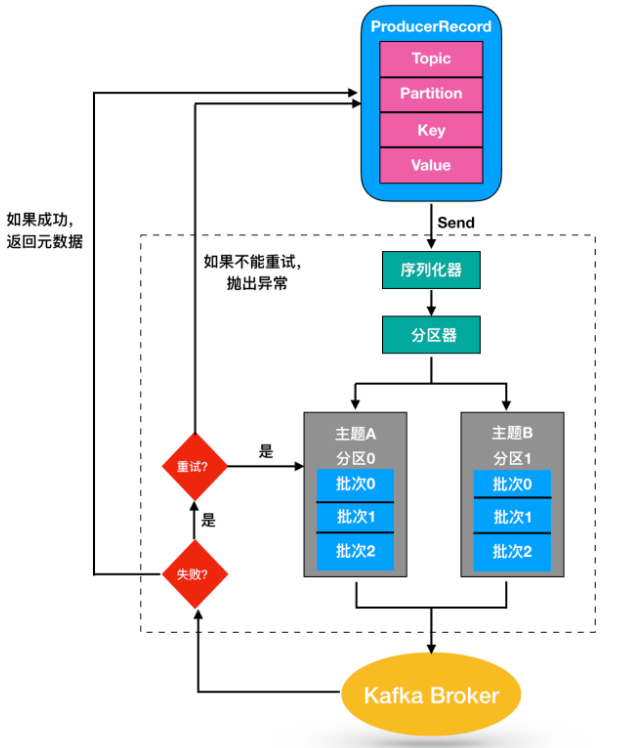 **说明** (1)新建`ProducerRecord`对象,包含目标主题和要发送的内容,也可以指定键或分区; (2)发送`ProducerRecord`对象时,生产者要把键和值对象序列化成字节数组,这样它们才能在网络上传输; (3)数据被传给分区器: + 如果ProducerRecord对象中指定了分区,那么分区器就不会再做任何事情,直接发送到该分区; + 如果发送时未指定,则默认使用key的hash值指定一个分区; + 如果发送时未指定消息key,则采用轮询的方式选择一个分区(这就是Kafka默认的分区策略)。 (4)这条记录被添加到一个记录批次里,这个批次里的所有消息会被发送到相同的主题和分区上,有一个独立的线程负责把这些记录批次发送到相应的broker上。 (5)服务器在收到这些消息时会返回一个响应: + 如果消息成功写入kafka,就返回一个`RecordMetaData`对象,它包含了主题和分区信息,以及记录在分区里的偏移量。 + 如果写入失败,则会返回一个错误。生产者在收到错误之后会尝试重新发送消息,几次之后如果还是失败,就返回错误信息。 #### ProducerRecord介绍 在发送消息时,需要将 producer 发送的数据封装成一个 `ProducerRecord` 对象,一个`ProducerRecord`表示一条待发送的消息记录。 ``` ProducerRecord(@NotNull String topic, Integer partition, Long timestamp, String key, String value, @Nullable Iterable<Header> headers) ProducerRecord(@NotNull String topic, Integer partition, Long timestamp, String key, String value) ProducerRecord(@NotNull String topic, Integer partition, String key, String value, @Nullable Iterable<Header> headers) ProducerRecord(@NotNull String topic, Integer partition, String key, String value) ProducerRecord(@NotNull String topic, String key, String value) ProducerRecord(@NotNull String topic, String value) ``` **参数说明** | 参数 | 说明 | | --------- | -------- | | topic | 所属主题 | | partition | 所属分区 | | key | 键值 | | value | 消息体 | | timestamp | 时间戳 | + 指明partition的情况下,直接将指明的值作为partition值; + 没有指明partition值,但有key的情况下,将key的hash值与topic的partition数目进行取余操作,得到partition值; + 即没有partition值又没有key的情况下,第一次调用时随机生成一个整数(后面每次调用在这个整数上自增),将这个值与topic可用的partition总数取余得到partition值,也就是常说的round-robin算法。 #### 总结 **因为一个topic可以有多个 Partition组成**,在进行传参时Topic是用户自己创建的所以可以必须指定,但是Partition是根据`topic名称+有序序号`由系统生成的,对于用户而言很难指定到某个具体的Partition。 那么分区器在发送消息的时候怎么知道要发送给哪个分区呢? 这时候生产者分区策略就派上用场了。 通过对上方**生产者发送消息流程**进行解读我们在前言中提到的第一个问题应该已经有了答案。 下面继续进行第二个问题的探索,生产者分区策略有哪些呢? ### 二、分区策略 #### 2.1 概述 **分区策略:决定生产者将消息发送到哪个分区的算法**,Kafka提供了默认的分区策略,也支持自定义的分区策略。 #### 2.2默认分区策略介绍 ##### **轮询策略** 也称 Round-robin 策略,即顺序分配。  **说明** 比如一个主题下有 3 个分区,那么第一条消息被发送到分区 0,第二条被发送到分区 1,第三条被发送到分区 2,以此类推。当生产第 4 条消息时又会重新开始,即将其分配到分区 0。 **总结** + 轮询策略是 Kafka Java 生产者 API 默认提供的分区策略; + 轮询策略的**负载均衡表现非常优秀**,总能保证消息**最大限度**地被平均分配到所有分区上,默认情况下它是最合理的分区策略。 ##### 随机策略 也称 `Randomness` 策略。所谓随机就是我们随意地将消息放置到任意一个分区上,如下面这张图所示。  如果要实现随机策略版的 partition 方法,很简单,只需要两行代码即可: ```java List partitions = cluster.partitionsForTopic(topic); return ThreadLocalRandom.current().nextInt(partitions.size()); ``` 先计算出该主题总的分区数,然后随机地返回一个小于它的正整数。本质上看随机策略也是力求将数据均匀地打散到各个分区,但从实际表现来看,它要逊于轮询策略,所以**如果追求数据的均匀分布,还是使用轮询策略比较好**。事实上,随机策略是老版本生产者使用的分区策略,在新版本中已经改为轮询了。 ##### 按消息键保序策略 也称 Key-ordering 策略。  **说明** 1. Kafka允许为每条消息定义**消息键**,简称为Key 2. Key可以是一个有明确业务含义的字符串:客户代码、部门编号、业务ID、用来表征消息的元数据等 3. 一旦消息被定义了Key,可以保证同一个Key的所有消息都进入到相同的分区里,由于每个分区下的消息处理都是**顺序**的,所以这个策略被称为**按消息键保序策略** 实现这个策略的 partition 方法同样简单,只需要下面两行代码即可: ```java List partitions = cluster.partitionsForTopic(topic); return Math.abs(key.hashCode()) % partitions.size(); ``` **总结** Kafka Java生产者的默认分区策略: - 如果**指定了Key**,采用**按消息键保序策略** - 如果**没有指定Key**,采用**轮询策略** ### 三、自定义分区策略 `kafka java api`提供了一个接口,用于自定义分区策略:`org.apache.kafka.clients.producer.Partitioner` ```java public interface Partitioner extends Configurable, Closeable { /** * Compute the partition for the given record. * * @param topic The topic name * @param key The key to partition on (or null if no key) * @param keyBytes The serialized key to partition on( or null if no key) * @param value The value to partition on or null * @param valueBytes The serialized value to partition on or null * @param cluster The current cluster metadata */ public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster); /** * This is called when partitioner is closed. */ public void close(); } ``` **说明** + `partition()`:计算给定记录的分区 **参数说明** | 参数 | 说明 | | ---------- | ----------------------------------------- | | topic | 需要传递的主题 | | key | 消息中的键值 | | keyBytes | 分区中序列化过后的key,byte数组的形式传递 | | value | 消息的 value 值 | | valueBytes | 分区中序列化后的值数组 | | cluster | 当前集群的原数据 | + `close()` : 继承了 `Closeable` 接口能够实现 close() 方法,在分区关闭时调用。 + `onNewBatch()`: 表示通知分区程序用来创建新的批次 如何想实现自定义分区策略,直接实现Partitioner接口,重写接口中的方法。 ### 四、总结 + ##### 轮询策略(默认分区策略) 优点:可以提供**非常优秀的负载均衡能力**,可以保证消息被平均分配到所有分区上。 缺点:**无法保证消息的有序性。** + ##### 随机策略 优点:消息的分区选择逻辑简单。 缺点:负载均衡能力一般,也无法保证消息的有序性 + **按消息键保序策略** 优点:可以保证相同key的消息被发送到相同的分区,因此可以**保证相同key的所有消息之间的顺序性。** 缺点:可能会产生数据倾斜 —— 取决于数据中key的分布,以及使用的hash算法。 附参考文章链接地址: http://zhongmingmao.me/2019/07/24/kafka-producer-partitioning/ https://www.cnblogs.com/yxb-blog/p/14794745.html
标签:
Kafka
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://lilinchao.com/archives/1515.html
上一篇
06.Kafka文件存储机制
下一篇
中秋随笔
评论已关闭
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
NLP
4
标签云
随笔
pytorch
链表
ajax
持有对象
Elasticsearch
并发编程
锁
JavaScript
Tomcat
Redis
DataWarehouse
CentOS
Docker
Java阻塞队列
FastDFS
Spring
稀疏数组
BurpSuite
SpringBoot
Livy
国产数据库改造
设计模式
散列
Ubuntu
Sentinel
FileBeat
Nacos
人工智能
JavaWEB项目搭建
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞
评论已关闭