李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
Hbase基础入门
Leefs
2021-02-12 PM
2002℃
0条
# 01.Hbase基础入门 ### 一、简史 HBase的原型是Google的BigTable论文,受到了该论文思想的启发,目前作为Hadoop的子项目来开发维护,用于支持结构化的数据存储。 *官方网站:http://hbase.apache.org* + 2006年Google发表BigTable白皮书 + 2006年开始开发HBase + 2008年将HBase弄成了Hadoop的子项目 + 2010年HBase成为Apache顶级项目 ### 二、Hbase概述 **HBase是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统**,利用HBASE技术可在廉价PC Server上搭建起大规模结构化存储集群。 HBase的目标是存储并处理大型的数据,更具体来说是仅需使用普通的硬件配置,就能够处理由成千上万的行和列所组成的大型数据。 HBase是Google Bigtable的开源实现,但是也有很多不同之处。 比如:Google Bigtable利用GFS作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统;Google运行MAPREDUCE来处理Bigtable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据;Google Bigtable利用Chubby作为协同服务,HBase利用Zookeeper作为对应。 **总结:Hbase是一款NoSQL数据库,面向列存储,用于存储处理海量数据。** ### 三、为什么使用Hbase 先说一下Mysql,我们都知道Mysql是一个关系型数据库,平时开发使用的非常频繁。一个网站或者系统最核心的表就是用户表,而当用户表的数据达到几千万甚至几亿级别的时候,对单条数据的检索将会耗费数秒甚至分钟级别。实际的情况可能更加复杂不堪。 看下边一张表: 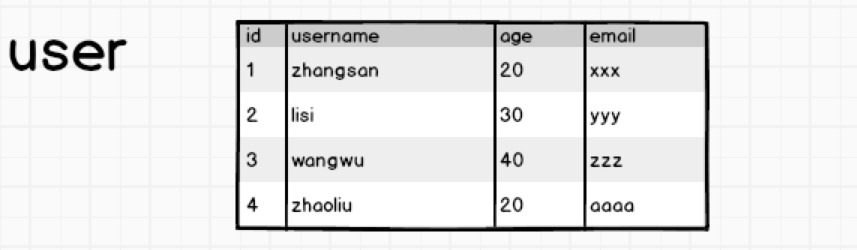 有这么一张用户表,假如我要根据id=1查询出来这条数据对应的用户姓名,很简单,会给我们返回zhangsan。但是,当我们查的时候,想一下,查名字的时候age和email会不会被查出来?答案是肯定的,Mysql的数据存储是以行为单位的,面向行存储。那问题就出现了,我只需要找出zhangsan的名字,却需要查询一整行的数据,如果列非常多,那么查询效率可想而知了。 查询的操作速度会受到以下两个因素的制约: + 表被并发的插入、编辑以及删除操作。 + 查询语句通常不是简单的对一个表进行操作,有可能是多个表关联后的复杂查询,甚至有可能是group by或者order by操作,此时,性能下降很明显。 如果一张表的列过多,会影响查询效率,我们称这样表为**宽表**。怎么优化呢,拆开来,**竖直拆分:**  这样的情况下,我们要查找username的时候只需要查找user_basic表,没有多余的字段,查询效率就会很快。 如果一张表的行过多,会影响查询效率,我们将这样的表称之为**高表**,可以采用**水平拆表**的方式提高效率:  这种水平拆分应用比较多的 场景就是日志表,日志信息每天产生很多,可以按月进行水平拆分,这样就实现了**高表变矮**。 这种拆分方式貌似可以解决宽表和高表的问题,但是如果有一天公司的业务变了,比如原来没有微信,现在有了微信,需要加入用户的微信字段。这时候需要改变表的结构信息,该怎么办?最简单的想法是多加一列,像这样:  多考虑一下就知道这样做很不妥帖,比如说有些早期用户没有微信,这一列是设置默认值还是采取其他的做法就得权衡一下。如果需要扩展很多的列出来,而且不是所有的用户都有这些属性,那么拓展起来就更加复杂了。 这时候,想到了JSON格式的字符串,这是一种以字符串的形式表示的对象,而且属性字段可以动态拓展,于是有了下边这种做法,两种做法加以对比:  这样存储数据它不挺好的嘛,HBase出来干嘛?Mysql有一点,数据达到一定的阈值,无论怎么优化,它都无法达到高性能的发挥。而大数据领域的数据,动辄PB级,这种存储应用明显是不能很好的满足需求的。针对上边的问题,HBase都有很好的解决方案。 ### 四、Hbase实现 高表宽表,数据列动态扩展,把提到的几个解决办法:水平垂直切分,列扩展方法,杂糅在一起。 有这么一张表,怕它又宽又高,又会动态扩展列,那么在设计之初,就把这个表给他拆开,为了列的动态拓展,直接存储JSON格式:  这样就解决了宽表问题,高表怎么办呢? 一个表的两部分,各存一部分行:  解决了高表,宽表,动态扩展列的问题。 如果还要进一步提高性能怎么办?Mysql->Redis 查询出来的数据放入到缓存中,下一次查询直接从缓存中拿数据。插入数据怎么办呢?也可以这样理解,我把要插入的数据放进缓存中,再也不用管了,直接由数据库从缓存拿数据插入到数据库。此时程序不需要等待数据插入成功,提高了并行工作的效率。 可是这样做有了很大的风险,服务器宕机的话,缓存中的数据没来得及插入到数据库中,那不就丢数据了嘛。参考Redis的持久化策略,可以给插入数据这个操作添加一个操作日志,用于持久化插入操作,宕机重启后从日志恢复。 这样设计架构就变成了这个样子:  上边这种解决方式,实际上就是HBase实现的大致思路,详细的内容会在后边慢慢说。 **总结:HBase就是一个面向列存储的非关系型数据库。** 两者的区别主要是:  HBase的存储时基于HDFS的,HDFS有着高容错性的特点,被设计用来部署在低廉的硬件上,而且它提供高吞吐量以访问应用程序的数据,支持那些有着超大数据集的应用程序。 基于Hadoop意味着HBase与生俱来的超强的扩展性和吞吐量。 HBase采用的是key/value的存储方式,这意味着,及时随着数据量的增大,也几乎不会导致查询性能的下降。HBase又是一个面向列存储的数据库,当表的字段很多时,可以把其中几个字段独立出来放在一部分机器上,而另外几个字段放到另一部分机器上,充分分散了负载的压力。如此复杂的存储结构和分布式的存储方式,带来的代价就是:即便是存储很少的数据,也不会很快。 > HBase并不是足够快,而是数据量很大的时候它慢的不明显。 **使用HBase使用条件** - 单表数据量超过千万,而且并发量很大; - 数据分析需求较弱,或者不需要那么实时灵活。 ### 五、HBase特点 | 特点 | 描述 | | ------------ | ------------------------------------------------------------ | | 大 | 一个表可以上亿行,上百万列。 | | 面向列 | 面向列表(簇)的存储和权限控制,列(簇)独立检索。 | | 稀疏 | 对于为空(NULL)的列,并不占用存储空间,因此,表可以设计的非常稀疏。 | | 无模式 | 每一行都有一个可以排序的主键和任意多的列,列可以根据需要动态增加,同一张表中不同的行可以有截然不同的列 | | 数据多版本 | 每个单元中的数据可以有多个版本,默认情况下,版本号自动分配,版本号就是单元格插入时的时间戳。 | | 数据类型单一 | HBase中的数据都是字符串,没有类型 |
标签:
Hbase
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://lilinchao.com/archives/1108.html
上一篇
FileBeat收集tomcat日志
下一篇
Hbase架构
评论已关闭
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
NLP
4
标签云
并发线程
排序
Golang
DataWarehouse
Docker
DataX
持有对象
SpringCloudAlibaba
Filter
工具
Stream流
Hbase
Flink
字符串
Spark SQL
JavaWeb
高并发
RSA加解密
二叉树
正则表达式
Thymeleaf
Elasticsearch
Spark Core
Flume
锁
VUE
ClickHouse
LeetCode刷题
Netty
CentOS
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞
评论已关闭