李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
Java
正文
Filebeat介绍
Leefs
2021-02-11 PM
2611℃
1条
# 03.Filebeat介绍 ### 一、简述 Filebeat是Beat成员之一,基于Go语言,无任何依赖,并且比logstash更加轻量,非常适合安装在生产机器上,不会带来过高的资源占用,轻量意味着简单,所以Filebeat并没有集成和logstash一样的正则处理功能,而是将收集的日志原样上报。 常用的Elastic Stack日志采集方案中,大部分的做法就是将所有节点的日志内容通过filebeat送到kafka消息队列,然后使用logstash集群读取消息队列内容,根据配置文件进行过滤。然后将过滤之后的文件输送到elasticsearch中,通过kibana去展示。 **filebeat和logstash比较**:logstash是jvm跑的,资源消耗比较大,启动一个logstash就需要消耗500M左右的内存,而filebeat只需要10来M内存资源。 ### 二、Filebeat组成 Filebeat由三个主要组成部分组成:**prospector**、**harvesters**和 **input**。 这些组件一起工作来读取文件并将事件数据发送到您指定的output。 ### 三、组件介绍 **3.1 harvesters介绍** + harvesters负责读取单个文件的内容。 + harvesters逐行读取每个文件,并将内容发送到output中。 + 每个文件都将启动一个harvesters。 + harvesters负责文件的打开和关闭,这意味着harvesters运行时,文件会保持打开状态。如果在收集过程中,即使删除了这个文件或者是对文件进行重命名,Filebeat依然会继续对这个文件进行读取,这时候将会一直占用着文件所对应的磁盘空间,直到Harvester关闭。默认情况下,Filebeat会一直保持文件的开启状态,直到超过配置的close_inactive参数,Filebeat才会把Harvester关闭。 **关闭Harvesters会带来的影响:** + file Handler将会被关闭,如果在Harvester关闭之前,读取的文件已经被删除或者重命名,这时候会释放之前被占用的磁盘资源。 + 当时间到达配置的scan_frequency参数,将会重新启动进行文件内容的收集。 + 如果在Havester关闭以后,移动或者删除了文件,Havester再次启动时,将会无法收集文件数据。 + 当需要关闭Harvester的时候,可以通过close_*配置项来控制。 **3.2 Prospector介绍** + Prospector(探测器)负责管理Harvsters,并且找到所有需要进行读取的数据源。 + 如果input type配置的是log类型,Prospector将会去配置度路径下查找所有能匹配上的文件,然后为每一个文件创建一个Harvster。 + 每个Prospector都运行在自己的Go routine里。 + **Filebeat目前支持两种Prospector类型:log和stdin。** + 每个Prospector类型可以在配置文件定义多个。 + log Prospector将会检查每一个文件是否需要启动Harvster,启动的Harvster是否还在运行,或者是该文件是否被忽略(可以通过配置 ignore_order,进行文件忽略)。如果是在Filebeat运行过程中新创建的文件,只要在Harvster关闭后,文件大小发生了变化,新文件才会被Prospector选择到。 **3.3 input介绍** - 一个input负责管理harvester,并找到所有要读取的源 - 如果input类型是log,则input查找驱动器上与已定义的glob路径匹配的所有文件,并为每个文件启动一个harvester - 每个input都在自己的Go例程中运行 ### 四、filebeat工作原理 Filebeat可以保持每个文件的状态,并且频繁地把文件状态从注册表里更新到磁盘。这里所说的文件状态是用来记录上一次Harvster读取文件时读取到的位置,以保证能把全部的日志数据都读取出来,然后发送给output。如果在某一时刻,作为output的ElasticSearch或者Logstash变成了不可用,Filebeat将会把最后的文件读取位置保存下来,直到output重新可用的时候,快速地恢复文件数据的读取。在Filebaet运行过程中,每个Prospector的状态信息都会保存在内存里。如果Filebeat出行了重启,完成重启之后,会从注册表文件里恢复重启之前的状态信息,让FIlebeat继续从之前已知的位置开始进行数据读取。 Prospector会为每一个找到的文件保持状态信息。因为文件可以进行重命名或者是更改路径,所以文件名和路径不足以用来识别文件。对于Filebeat来说,都是通过实现存储的唯一标识符来判断文件是否之前已经被采集过。 如果在你的使用场景中,每天会产生大量的新文件,你将会发现Filebeat的注册表文件会变得非常大。这个时候,你可以参考([the section called “Registry file is too large?](https://www.elastic.co/guide/en/beats/filebeat/current/faq.html#reduce-registry-size)[edit](https://github.com/elastic/beats/edit/5.1/filebeat/docs/faq.asciidoc)),来解决这个问题。 ### 五、Filebeat架构 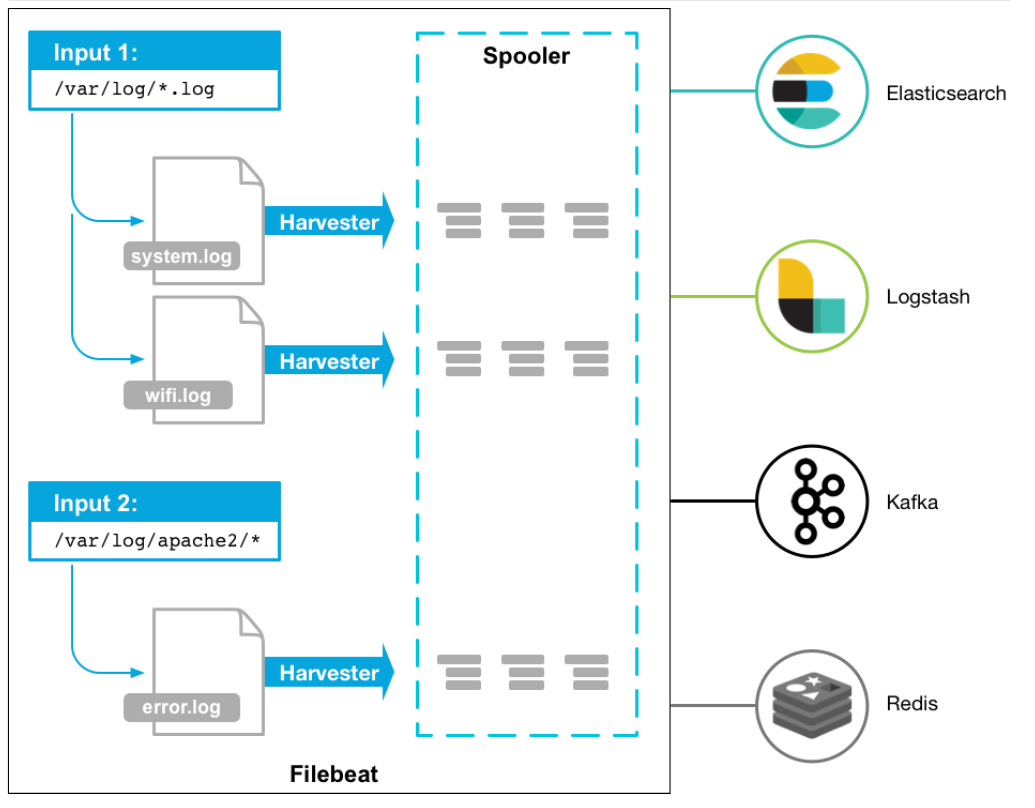 + 当你开启filebeat程序的时候,它会启动一个或多个探测器(prospectors)去检测你指定的日志目录或文件,对于探测器找出的每一个日志文件 + filebeat启动收割进程(harvester),每一个收割进程读取一个日志文件的新内容,并发送这些新的日志数据到处理程序(spooler) + 处理程序会集合这些事件,最后filebeat会发送集合的数据到你指定的地点。
标签:
Elasticsearch
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://lilinchao.com/archives/1083.html
上一篇
Beats简介
下一篇
FileBeat安装步骤
取消回复
评论啦~
提交评论
唉呀 ~ 仅有一条评论
11
1
回复
2022-10-19 17:19
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
标签云
Tomcat
Spark Streaming
稀疏数组
散列
Python
Java工具类
锁
机器学习
数据结构
DataWarehouse
Elasticsearch
Golang基础
序列化和反序列化
持有对象
Java编程思想
JVM
国产数据库改造
ClickHouse
Stream流
HDFS
NIO
Spark SQL
Spark
设计模式
Yarn
并发编程
哈希表
nginx
JavaWEB项目搭建
gorm
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞
1