李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
Java
正文
ElasticSearch分析和分析器
Leefs
2021-02-09 PM
2719℃
2条
# 06.ElasticSearch分析和分析器 ### 前言 本文先从一个例子来进行引入。 ```json #创建索引,并添加两行数据 PUT my_test/_doc/1 { "name":"李林超博客", "age":"23" } PUT my_test/_doc/2 { "name":"李林超博客2", "age":"34" } ``` 当我们对其中名称为age的字段进行检索时,得到如下结果 ```json GET /my_test/_search { "query": { "constant_score": { "filter": { "term": { "age": 23 } }, "boost": 1.2 } } } ``` 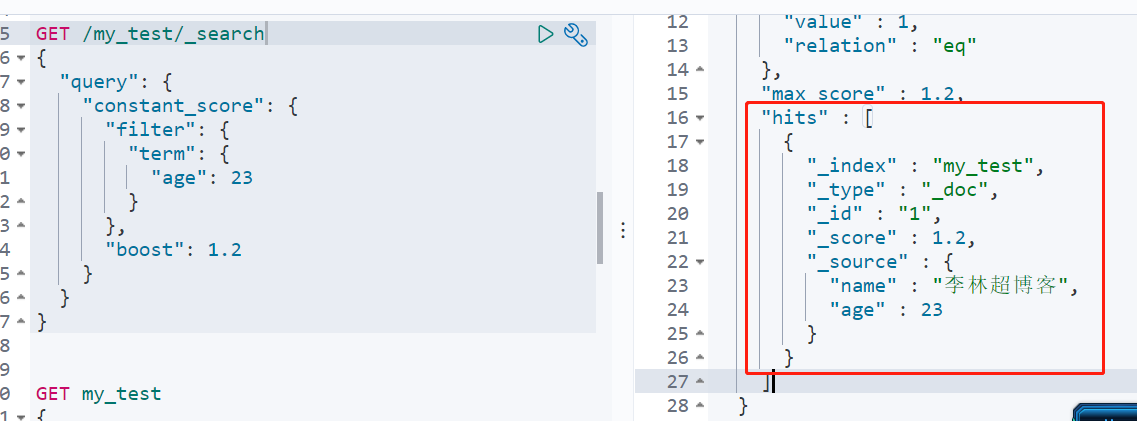 可以检索到我们想要的结果,但是我们用name字段进行检索我们得到如下结果。  此时,输出的结果为空,说明name中的值并未匹配到。 ### 一、分析器的作用 把输入的文本块按照一定的策略进行分解,并建立倒排索引。在Lucene的架构中,这个过程由分析器(analyzer)完成。 ### 二、分析器的主要组成 + **字符过滤器(character filter)** 接收原字符流,通过添加、删除或者替换操作改变原字符流。例如:去除文本中的html标签,或者将罗马数字转换成阿拉伯数字等。一个字符过滤器可以有`零个或者多个`。 + **分词器(tokenizer)** 简单的说就是将一整段文本拆分成一个个的词。例如拆分英文,通过空格能将句子拆分成一个个的词,但是对于中文来说,无法使用这种方式来实现。在一个分词器中,`有且只有一个`tokenizeer + **Token 过滤器(token filters)** 将切分的单词添加、删除或者改变。例如将所有英文单词小写,或者将英文中的停词`a`删除等。在`token filters`中,不允许将`token(分出的词)`的`position`或者`offset`改变。同时,在一个分词器中,可以有零个或者多个`token filters`. **示例演示:** 将包含html标签的字段:`<p>I'm so <b>happy</b>!</p>`进行转化。  最后通过分词器转化成`I'M`、`SO`、`HAPPY`。 ### 三、索引和搜索分词 文本分词会发生在两个地方: + `创建索引`:当索引文档字符类型为`text`时,在建立索引时将会对该字段进行分词。 + `搜索`:当对一个`text`类型的字段进行全文检索时,会对用户输入的文本进行分词。 ### 四、内置分析器 **1、配置分析器** 默认ES使用`standard analyzer`,如果默认的分词器无法符合你的要求,可以自己配置。 **2、分析器测试** 可以通过`_analyzer`API来测试分词的效果。 ```json POST _analyze { "analyzer": "standard", "text": "The quick brown fox" } ``` 同时也可以按照下面的规则组合使用: > - 0个或者多个`character filters` > - 一个`tokenizer` > - 0个或者多个`token filters` ```json POST _analyze { "char_filter": ["html_strip"], //字符过滤器:去除html标签,进行特殊符号转换 "tokenizer": "standard", //分析器:通过空格,符号进行分割 "filter": ["uppercase"], //Token 过滤器:将小写字母转化成大写字母 "text": "<p>I'm so <b>happy</b>!</p>" } ``` **3、内置分析器** Elasticsearch还附带了可以直接使用的预包装的分析器。接下来我们会列出最重要的分析器。为了证明它们的差异,我们看看每个分析器会从下面的字符串得到哪些词条: ```json "Set the shape to semi-transparent by calling set_trans(5)" ``` + **标准分析器** 标准分析器是Elasticsearch默认使用的分析器。它是分析各种语言文本最常用的选择。它根据 Unicode 联盟 定义的 *单词边界* 划分文本。删除绝大部分标点。最后,将词条小写。它会产生 ```json set, the, shape, to, semi, transparent, by, calling, set_trans, 5 ``` + **简单分析器** 简单分析器在任何不是字母的地方分隔文本,将词条小写。它会产生 ```json set, the, shape, to, semi, transparent, by, calling, set, trans ``` + **空格分析器** 空格分析器在空格的地方划分文本。它会产生 ```json Set, the, shape, to, semi-transparent, by, calling, set_trans(5) ``` + **语言分析器** 特定语言分析器可用于很多语言。它们可以考虑指定语言的特点。例如, `英语` 分析器附带了一组英语无用词(常用单词,例如 `and` 或者 `the` ,它们对相关性没有多少影响),它们会被删除。 由于理解英语语法的规则,这个分词器可以提取英语单词的 *词干* 。 ``` set, shape, semi, transpar, call, set_tran, 5 ``` 注意看 `transparent`、 `calling` 和 `set_trans` 已经变为词根格式。 ### 五、自定义分析器 官网示例: 作为示范,让我们一起来创建一个自定义分析器吧,这个分析器可以做到下面的这些事: 1. 使用 html清除 字符过滤器移除HTML部分。 2. 使用一个自定义的 映射 字符过滤器把 & 替换为 " and " : ```json "char_filter": { "&_to_and": { "type": "mapping", "mappings": [ "&=> and "] } } ``` 3. 使用 标准 分词器分词。 4. 小写词条,使用 小写 词过滤器处理。 5. 使用自定义 停止 词过滤器移除自定义的停止词列表中包含的词: ```jsoN "filter": { "my_stopwords": { "type": "stop", "stopwords": [ "the", "a" ] } } ``` 我们的分析器定义用我们之前已经设置好的自定义过滤器组合了已经定义好的分词器和过滤器: ```json "analyzer": { "my_analyzer": { "type": "custom", "char_filter": [ "html_strip", "&_to_and" ], "tokenizer": "standard", "filter": [ "lowercase", "my_stopwords" ] } } ``` 汇总起来,完整的 创建索引 请求 看起来应该像这样: ```json PUT /my_index { "settings": { "analysis": { "char_filter": { "&_to_and": { "type": "mapping", "mappings": [ "&=> and "] }}, "filter": { "my_stopwords": { "type": "stop", "stopwords": [ "the", "a" ] }}, "analyzer": { "my_analyzer": { "type": "custom", "char_filter": [ "html_strip", "&_to_and" ], "tokenizer": "standard", "filter": [ "lowercase", "my_stopwords" ] }} } } } ``` 索引被创建以后,使用 analyze API 来 测试这个新的分析器: ```json GET /my_index1/_analyze { "analyzer":"my_analyzer", "text": "The quick & brown fox" } ``` 拷贝为 CURL在 SENSE 中查看 下面的缩略结果展示出我们的分析器正在正确地运行: ```json { "tokens": [ { "token": "quick", "start_offset": 4, "end_offset": 9, "type": "<ALPHANUM>", "position": 1 }, { "token": "and", "start_offset": 10, "end_offset": 11, "type": "<ALPHANUM>", "position": 2 }, { "token": "brown", "start_offset": 12, "end_offset": 17, "type": "<ALPHANUM>", "position": 3 }, { "token": "fox", "start_offset": 18, "end_offset": 21, "type": "<ALPHANUM>", "position": 4 } ] } ```
标签:
Elasticsearch
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://lilinchao.com/archives/1027.html
上一篇
ElasticSearch之Mapping(映射)介绍
下一篇
ElasticSearch安装IK分词器
评论已关闭
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
NLP
4
标签云
Hadoop
Java
HDFS
国产数据库改造
MyBatis-Plus
Hive
查找
Yarn
稀疏数组
SQL练习题
SpringBoot
哈希表
Golang基础
MyBatis
Spark Core
Scala
机器学习
Stream流
JavaWeb
SpringCloud
高并发
Netty
FileBeat
Nacos
Jquery
FastDFS
MyBatisX
二叉树
Filter
Ubuntu
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞
评论已关闭