
34.Flink保存点(Savepoints)介绍
[TOC]一、Savepoint概念Savepoint是依据Flink checkpointing机制所创建的流作业执行状态的一致镜像。可以使用Savepoint进行 Flink 作业的停止与重启、fork 或者更新。Savepoint由两部分组成:稳定存储(列入 HDFS,S3,…) 上包含二进制文件的目录(通常很大)元数据文件(相对较小)稳定存储上的文件表示作业执行状态的数据镜像。 Sa...
33.Flink重启策略
[TOC]前言 Flink支持不同的重启策略,这些重启策略控制着job失败后如何重启。集群可以通过默认的重启策略来重启,这个默认的重启策略通常在未指定重启策略的情况下使用,而如果Job提交的时候指定了重启策略,这个重启策略就会覆盖掉集群的默认重启策略。一、概述Flink默认重启策略可以通过配置文件flink-conf.yaml来进行配置,通过配置参数restart-strat...
32.Flink Checkpoint配置
前言 Flink 中的每个方法或算子都能够是有状态的。状态化的方法在处理单个元素/事件的时候存储数据,让状态成为使各个类型的算子更加精细的重要部分。为了让状态容错,Flink 需要为状态添加 checkpoint(检查点)。Checkpoint 使得 Flink 能够恢复状态和在流中的位置,从而向应用提供和无故障执行时一样的语义。一、开启与配置 Checkpoint默认情况下...

31.Flink容错机制介绍
[TOC]前言 作为分布式系统,尤其是对延迟敏感的实时计算引擎,Apache Flink 需要有强大的容错机制,以确保在出现机器故障或网络分区等不可预知的问题时可以快速自动恢复并依旧能产生准确的计算结果。 事实上,Flink 有一套先进的快照机制来持久化作业状态,确保中间数据不会丢失,这通常需要和错误恢复机制配合使用。 在遇到错误时,Flink...
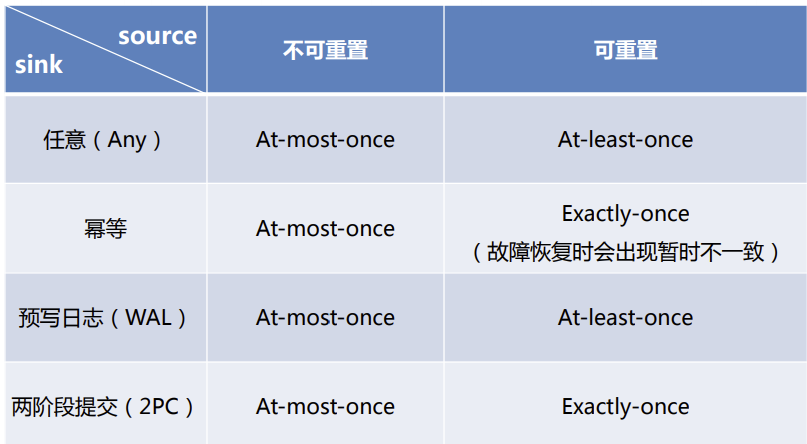
30.Flink状态一致性
[TOC]前言当在分布式系统中引入状态时,自然也引入了一致性问题。状态一致性的本质就是成功处理故障并恢复前后的结果的正确性级别。也就是说在成功处理故障并恢复之后得到的结果,与没有发生任何故障时得到的结果相比,前者到底有多正确?举例来说,假设要对最近一小时登录的用户计数。在系统经历故障之后,计数结果是多少?如果有偏差,是有漏掉的计数(最多一次)还是重复计数(最少一次)?一、一致性级别在流处理中...