李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
30.Flink状态一致性
Leefs
2022-02-13 PM
1264℃
0条
[TOC] ### 前言 当在分布式系统中引入状态时,自然也引入了一致性问题。 状态一致性的本质就是**成功处理故障并恢复前后的结果的正确性级别。** 也就是说在成功处理故障并恢复之后得到的结果,与没有发生任何故障时得到的结果相比,前者到底有多正确? 举例来说,假设要对最近一小时登录的用户计数。在系统经历故障之后,计数结果是多少? 如果有偏差,是有漏掉的计数(最多一次)还是重复计数(最少一次)? ### 一、一致性级别 在流处理中,一致性可以分为三个级别: + **at-most-once(最多一次)**:当任务故障时,最简单的做法是什么都不干,既不恢复丢失的状态,也不重播丢失的数据。At-most-once语义的含义是最多处理一次事件。 + **at-least-once(至少一次)**:这表示计数结果可能大于正确值,但绝不会小于正确值。也就是说,计数程序在发生故障后可能多算,但是绝不会少算。 + **exactly-once(精确一次)**:恰好处理一次是最严格的保证,也是最难实现的。恰好处理一次语义不仅仅意味着没有事件丢失,还意味着针对每一个数据,内部状态仅仅更新一次。 Flink的一个重大价值在于,**它既保证了exactly-once,也具有低延迟和高吞吐的处理能力。** ### 二、端到端(end-to-end)状态一致性 目前我们看到的一致性保证都是由流处理器实现的,也就是说**都是在Flink流处理器内部保证的**; 而在真实应用中,流处理应用除了流处理器以外还包含了数据源(例如 Kafka)和输出到持久化系统。 即端到端一致性指的是从Source-Flink内部程序-Sink持久化系统,状态的一致性即结果的正确性贯穿了整个流处理应用的始终。 每一个组件都保证了它自己的一致性,**整个端到端的一致性级别取决于所有组件中一致性最弱的组件。** **具体可以划分如下:** + **内部保证**:依赖checkpoint + **source端**:需要外部源可重设数据的读取位置(kafka的offset) + **sink端**:需要保证从故障恢复时,数据不会重复写入外部系统 **而对于sink端,又有两种具体的实现方式:** + 幂等(Idempotent)写入。 + 事务性(Transactional)写入。 #### 幂等写入 所谓幂等操作,是说一个操作,可以重复执行很多次,但只导致一次结果更改,也就是说,后面再重复执行就不起作用了。 但是它的结果会有一个渐变的流程,例如求最大温度: **1->2->10**,此时故障从上一检查点处重新计算,**2->10->12**。最终的Sink数据流为**1->2->10->2->10->12**。虽然最终结果无误,但是流程看起来不好,如果这些数据要实时展示,则会给人误解。 #### 事务性写入 需要构建事务来写入外部系统,构建的事务对应着checkpoint,等到checkpoint真正完成的时候,才把所有对应的结果写入 sink 系统中。 对于事务性写入,具体又有两种实现方式:**预写日志(WAL)和两阶段提交(2PC)。** `DataStream API`提供了`GenericWriteAheadSink`模板类和`TwoPhaseCommitSinkFunction` 接口,可以方便地实现这两种方式的事务性写入。 **注意** + 预写日志(Write-Ahead-Log,WAL)并不是真正的`exactly-once`,当批量写入Sink时,如果中途出错,从checkpoint回放数据,则会导致数据重复插入; + 两阶段提交(2PC)才是真正的`exactly-once`,但是它需要写入的系统支持事务,并且事务的超时时间最好和checkpoint的超时时间一致。 **预写日志(Write-Ahead-Log,WAL)** + 把结果数据先当成状态保存,然后在收到checkpoint完成的通知时, 一次性写入sink系统; + 简单易于实现,由于数据提前在状态后端中做了缓存,所以无论什么 sink 系统,都能用这种方式一批搞定; + `DataStream API`提供了一个模板类:`GenericWriteAheadSink`,来实现这种事务性sink。 **两阶段提交(Two-Phase-Commit,2PC)** + 对于每个checkpoint,sink 任务会启动一个事务,并将接下来所有接收的数据添加到事务里; + 然后将这些数据写入外部 sink 系统,但不提交它们 —— 这时只是 “预提交”; + 当它收到 checkpoint 完成的通知时,它才正式提交事务,实现结果的真正写入 ; + 这种方式真正实现了 exactly-once,它需要一个提供事务支持的外部 sink 系统; + Flink提供了 `TwoPhaseCommitSinkFunction` 接口。 **要求** (1)外部sink系统必须提供事务支持,或者sink任务必须能够模拟外部系统上的事务; (2)在checkpoint的间隔期间里,必须能够开启一个事务并接受数据写入; (3)在收到checkpoint完成的通知之前,事务必须是“等待提交”的状态。在故障恢复的情况下,这可能需要一些时间。如果这个时候sink系统关闭事务(例如超时了),那么未提交的数据就会丢失; (4)sink任务必须能够在进程失败后恢复事务; (5)提交事务必须是幂等操作 ### 三、不同 Source 和 Sink 的一致性保证 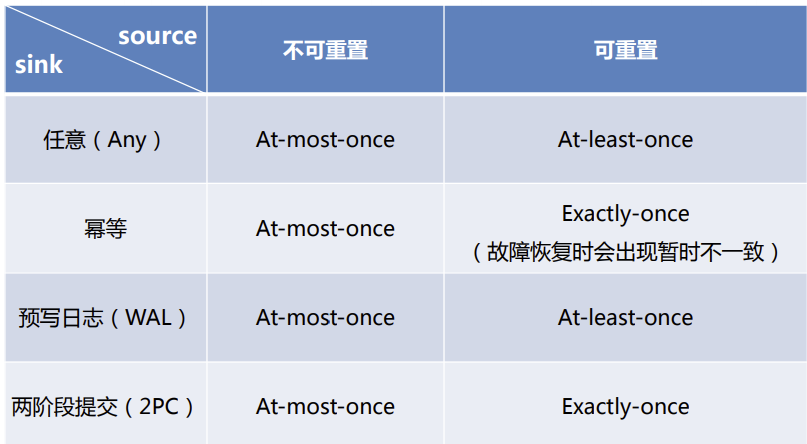 ### 四、Flink+Kafka端到端状态一致性的保证 + **内部**:利用 checkpoint 机制,把状态存盘,发生故障的时候以恢复,保证内部的状态一致性 + **source**: `kafka consumer`作为source,可以将偏移量保存下来, 如果后续任务出现了故障,恢复的时候可以由连接器重置偏移量,重新消费数据,保证一致性 + **sink**: `kafka producer`作为sink,采用两阶段提交sink,需要实现一个`TwoPhaseCommitSinkFunction` *附参考文章链接:* *https://awslzhang.top/2021/01/02/Flink%E7%8A%B6%E6%80%81%E7%AE%A1%E7%90%86/*
标签:
Flink
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://lilinchao.com/archives/1888.html
上一篇
29.Flink状态后端(State Backends)
下一篇
31.Flink容错机制介绍
评论已关闭
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
NLP
4
标签云
Spring
SpringCloudAlibaba
JavaWEB项目搭建
栈
nginx
Flink
Shiro
正则表达式
FastDFS
锁
Http
Java阻塞队列
Spark
Map
并发编程
Elasticsearch
并发线程
高并发
随笔
Java
RSA加解密
Hbase
递归
容器深入研究
排序
BurpSuite
FileBeat
字符串
NIO
Beego
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞
评论已关闭