ELK生命周期管理使用详解
[TOC]前言一般在使用ELK对日志进行收集时,为了避免单个索引文件过大,通常按日期来对日志做切割,根据日期对产生的日志生成相应的索引。索引名称通常如下方所示:nginx_log-2022.01.01 nginx_log-2022.01.02 nginx_log-2022.01.03 nginx_log-2022.01.04 nginx_log-2022.01.05上方是从nginx采集过来...
09.Flink任务调度原理
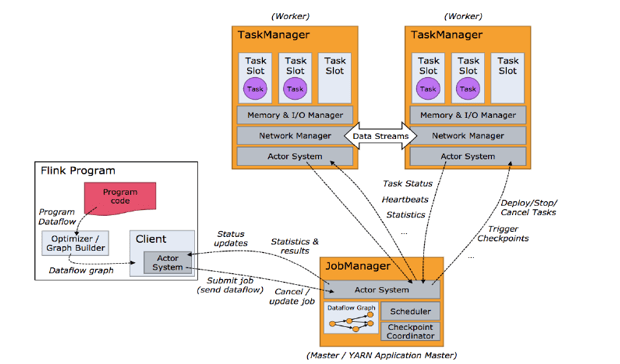
[TOC]一、任务调度原理客户端不是运行时和程序执行的一部分 , 但它用于准备并发送dataflow(JobGraph)给 Master(JobManager),然后,客户端断开连接或者维持连接以等待接收计算结果。当Flink集群启动后,首先会启动一个JobManger和一个或多个的TaskManager。由Client提交任务给JobManager,JobManager再调度任务到各个Ta...
08.Flink任务提交流程
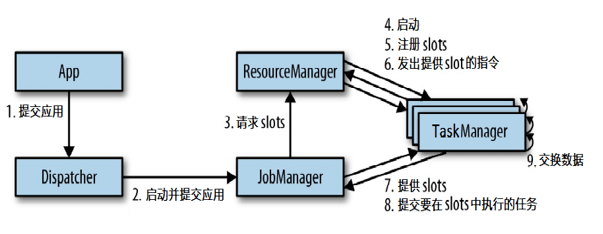
[TOC]一、Flink运行时架构Flink 客户端提交Flink作业到Flink集群Stream Graph 和 Job Graph构建JobManager资源申请任务调度应用容错TaskManager接收JobManager 分发的子任务,管理子任务任务处理(消费数据、处理数据)二、Standalone模式任务提交流程说明(1)App程序通过rest接口将应用提交给Dispatcher;...
07.Flink运行时组件
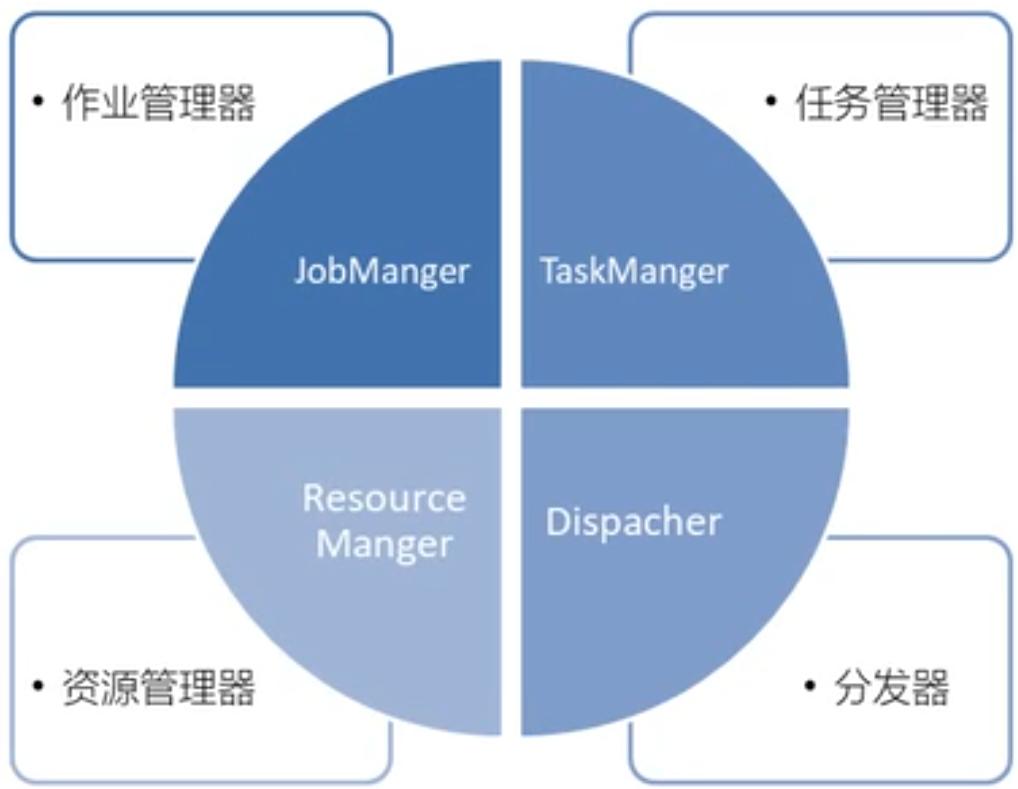
[TOC]前言本篇将介绍Flink的四大组件,先在开头做一个简单的概要总结:JobManager:分配任务,调度checkpoint做快照TaskManager:执行任务ResourceManager:资源管理器,分配资源,管理资源Dispacher:方便提交任务的接口,WebUI一、概述Flink 运行时架构主要包括四个不同的组件,它们会在运行流处理应用程序时协同工作:作业管理器(JobM...
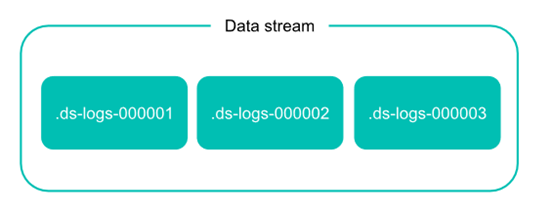
【转载】Elastic Stack之Data Stream的概念
[TOC]时序性数据时间序列数据( time series data )是在不同时间上收集到的数据,用于所描述现象随时间变化的情况。这类数据反映了某一事物、现象等,随时间的变化状态或程度。总的来说,这类数据主要基于时间特性明显,随着时间的流逝,往往过去时间的数据没有现在时间的重要或者敏感。对于 Elastisearch 处理时序性数据,有人总结了主要有以下特点:由时间戳 + 数据组成。基于时...
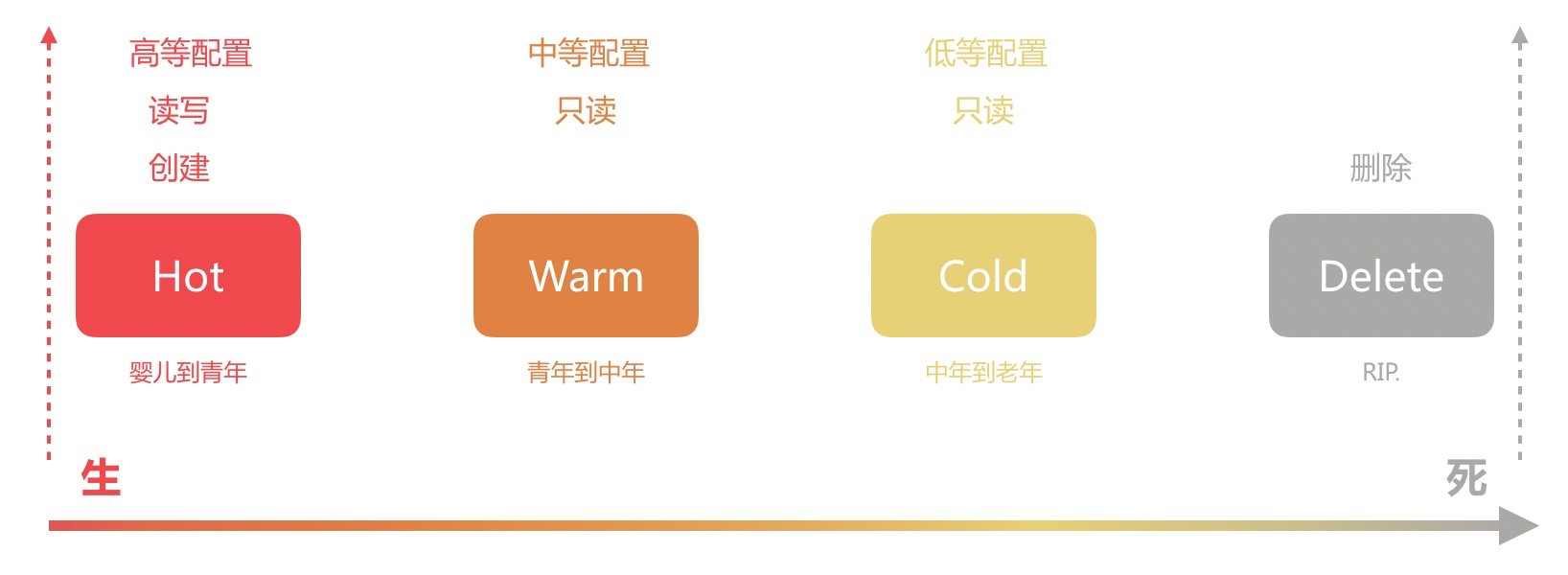
Elasticsearch索引生命周期管理
[TOC]前言在ELK架构中,使用Elasticsearch来存储系统日志时,有如下典型的特点:数据量非常大经常访问新增的数据,随着时间的推移,数据的价值也在逐渐降低随着数据量的增大,Elasticsearch创建索引的数量也在不断增长,这个时候就需要对 索引 进行一定策略的维护管理甚至是删除清理,否则随着数据量越来越多除了浪费磁盘与内存空间之外,还会严重影响 Elasticsearch 的...
Cerebro安装教程
[TOC]前言准备环境:JDK1.8CentOS 7.X一、介绍Cerebro是以前的 Elasticsearch插件Elasticsearch Kopf 的演变,这不适用于 Elasticsearch 版本5.x或更高版本,这是由于删除了site plugins。Cerebro 是查看分片分配和最有用的界面之一通过图形界面执行常见的索引操作。 完全开放源,并且它允许您添加用户,密码或 LD...
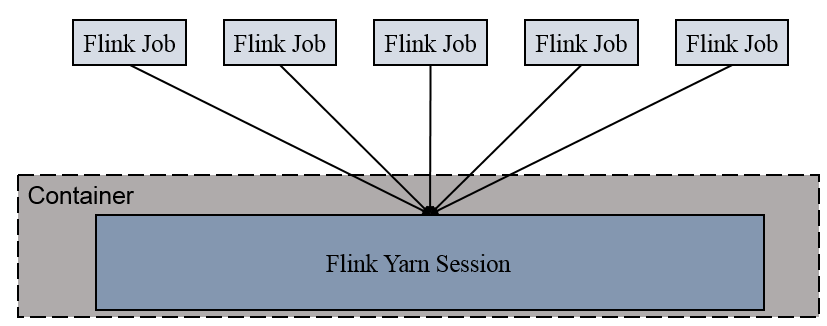
06.Flink Yarn模式介绍
[TOC]前言Flink的Standalone和on Yarn模式都属于集群运行模式,但是有很大的不同,在实际环境中,使用Flink on Yarn模式者居多。Standalone和on Yarn模式的最大不同点是管理资源的不同:Standalone模式通过Flink自身来管理集群资源on Yarn模式通过Hadoop Yarn来对集群资源进行管理一、概述 以Yarn模式部署...
05.Flink Standalone模式单机版安装
[TOC]一、概述1.1 介绍flink的 standalone(standalone deploy mode)部署模式,指的是flink直接在操作系统上启动flink相关服务如client, jobmanager, taskmanager,而不依赖其它资源管理框架如yarn, mesos, k8s进行资源管理。此时是由flink直接来进行集群资源管理的,比如监控和重启失败的服务进程,分配和...