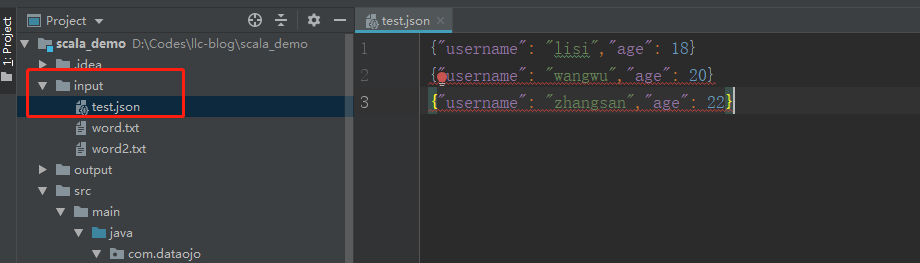
03.IDEA创建SparkSQL环境对象
03.IDEA创建SparkSQL环境对象一、引入坐标依赖<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.12</artifactId> <version>3.0.0</version> </dependency>在IDEA的pom.xml文件中引入以上坐标依赖,版本和SparkCore类似。本次使用的Spark版本是3.0.0Scala版本是2.12二、创建SparkSQ...
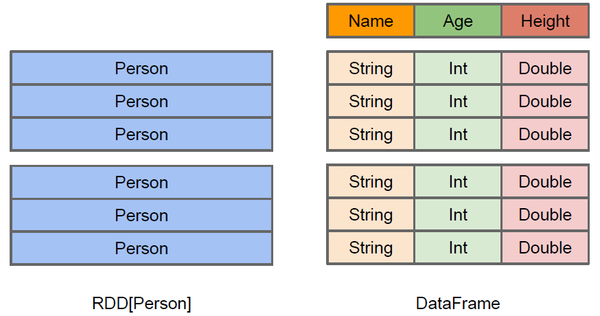
02.SparkSQL数据模型DataFrame和DataSet介绍
02.SparkSQL数据模型DataFrame和DataSet介绍前言本篇在上篇介绍SparkSQL概念的基础上对DataFrame和DataSet概念进行扩展一、DataFrame介绍1.1 DataFrame概念DataFrame的前身是SchemaRDD,从Spark 1.3.0开始SchemaRDD更名为DataFrame。与SchemaRDD的主要区别是:DataFrame不再直接继承自RDD,而是自己实现了RDD的绝大多数功能。你仍旧可以在DataFrame上调用rdd方法将其转换为一个RDD。在Spark中,DataFrame是一种以RDD为基础的分布式数据集,类似于传统...
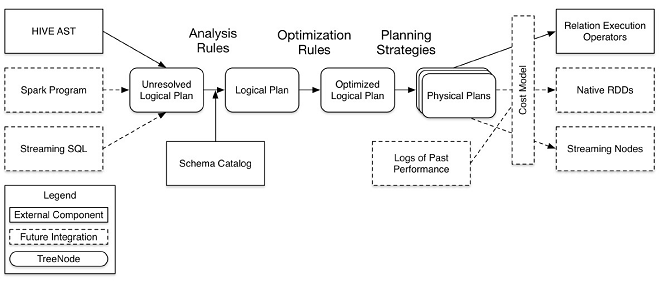
01.SparkSQL概述
01.SparkSQL概述一、简介spark SQL是spark的一个模块,主要用于进行结构化数据的处理。它提供的最核心的编程抽象就是DataFrame。 和基本的Spark RDD API不同的是Spark SQL提供了更多关于数据结构和正在执行的计算的信息。 在内部,Spark SQL使用这些额外的信息来执行额外的优化。可以使用SQL或者Dataset API与Spark SQL进行交互。二、发展历程1.0以前Shark,SparkSQL的前身是Shark。但是,随着Spark的发展,Shark对于Hive的太多依赖 (如采用Hive的语法解析器、查询优化器等等),制约了Spark的...
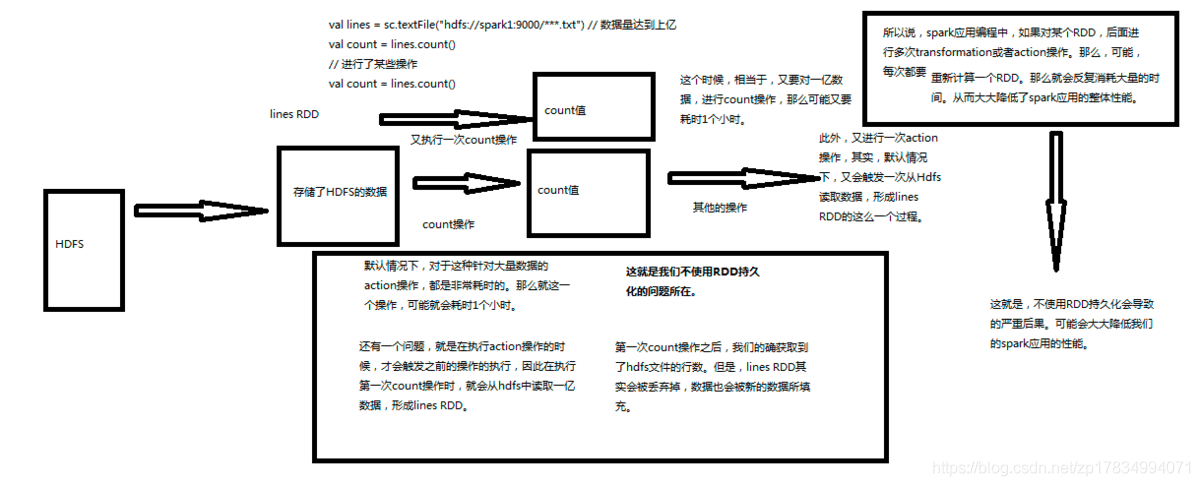
10.【转载】Spark RDD持久化
10.【转载】Spark RDD持久化一、什么是持久化?持久化的意思就是说将RDD的数据缓存到内存中或者持久化到磁盘上,只需要缓存一次,后面对这个RDD做任何计算或者操作,可以直接从缓存中或者磁盘上获得,可以大大加快后续RDD的计算速度。二、为什么要持久化?在之前的文章中讲到Spark中有tranformation和action两类算子,tranformation算子具有lazy特性,只有action算子才会触发job的开始,从而去执行action算子之前定义的tranformation算子,从hdfs中读取数据等,计算完成之后,Spark会将内存中的数据清除,这样处理的好处是避免了OO...
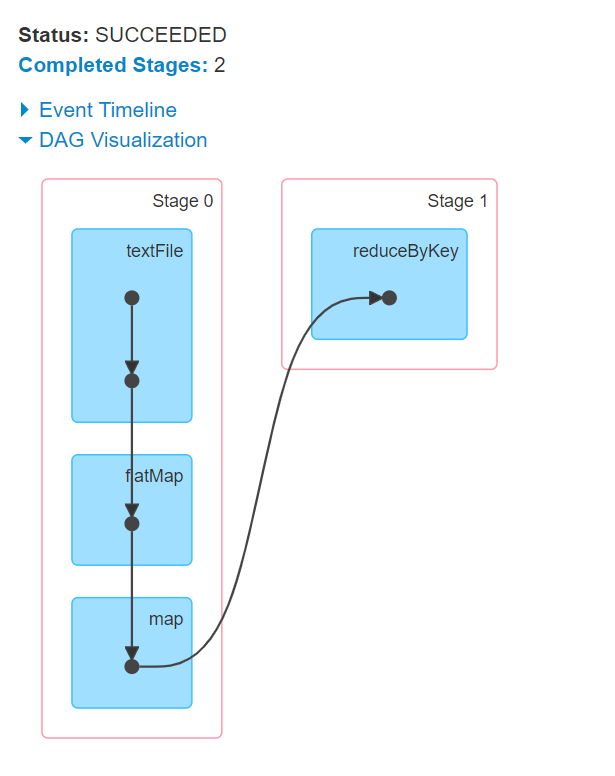
09.【转载】Spark RDD任务划分
09.【转载】Spark RDD任务划分一、DAG有向无环图生成1.1 DAG是什么DAG(Directed Acyclic Graph) 叫做有向无环图(有方向,无闭环,代表着数据的流向),原始的RDD通过一系列的转换就形成了DAG。下图是基于单词统计逻辑得到的DAG有向无环图二、DAG划分stage2.1 stage是什么一个Job会被拆分为多组Task,每组任务被称为一个stagestage表示不同的调度阶段,一个spark job会对应产生很多个stagestage类型一共有2种:ShuffleMapStage最后一个shuffle之前的所有变换的Stage叫ShuffleMap...
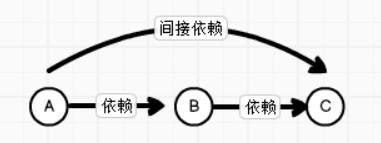
08.Spark RDD依赖关系
08.Spark RDD依赖关系一、RDD血缘关系1.1 概述RDD只支持粗粒度转换,即在大量记录上执行的单个操作。将创建RDD的一系列Lineage(血统)记录下来,以便恢复丢失的分区。RDD的Lineage会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。由于RDD中是不记录数据的,为了实现分布式计算中的容错 , RDD必须记录RDD之间的血缘关系1.2 图解血缘关系依赖关系A和B,B和C之间是直接依赖A和C之间是间接依赖血缘关系相邻的两个RDD的关系称之为依赖关系,新的RDD依赖于旧的RDD,多个连续的RDD的依赖...

07.Spark RDD序列化
07.Spark RDD序列化一、闭包检查 从计算的角度, 算子以外的代码都是在 Driver 端执行, 算子里面的代码都是在 Executor 端执行。 那么在 scala 的函数式编程中,就会导致算子内经常会用到算子外的数据,这样就形成了闭包的效果,如果使用的算子外的数据无法序列化,就意味着无法传值给 Executor 端执行,就会发生错误,所以需要在执行任务计算前,检测闭包内的对象是否可以进行序列化,这个操作我们称之为闭包检测。Scala2.12 版本后闭包编译方式发生了改变。二、序列化方法和属性从计算的角度, 算子以外的代码都是在 Driver 端...
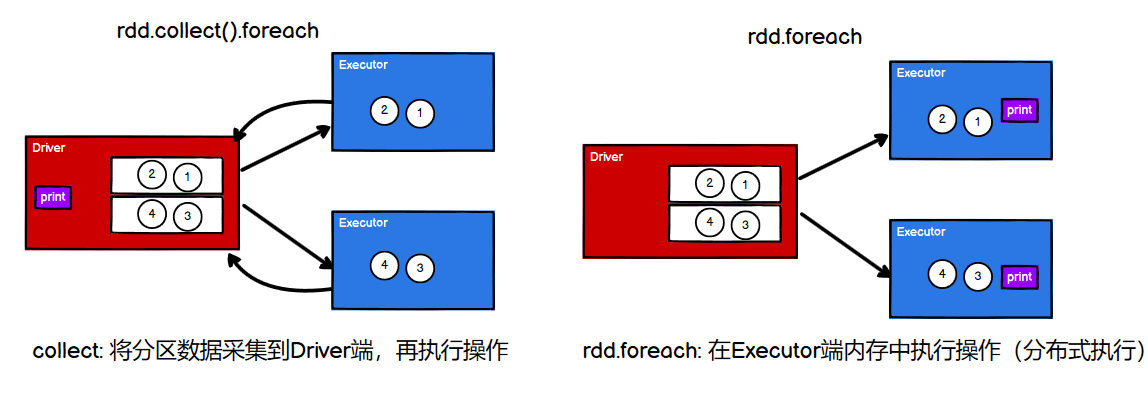
06.【转载】Spark RDD行动算子
[TOC]行动算子如何理解行动算子?val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4)) // 转换算子:将旧的RDD封装为新的RDD,形成transform chain,不会执行任何Job val mapRdd: RDD[Int] = rdd.map(_ * 2) // 行动算子:其实就是触发作业(Job)执行的方法,返回值不再是RDD mapRdd.collect()collect()等行动算子在底层调用环境对象的runJob方法,会创建ActiveJob,并提交执行。如果只有转换算子,而没有行动算子,那么Job不会执行,只是功能上的封...

05.【转载】Spark RDD转换算子
[TOC]前言转换算子RDD 根据数据处理方式的不同,将算子整体上分为 Value 类型、双 Value 类型 和 Key-Value类型。Value类型mapdef map(f: T => U): RDD[U]说明:将RDD中类型为T的元素,一对一地映射为类型为U的元素,这里的转换可以是类型的转换,也可以是值的转换val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4)) // 值的转换 ==> List(2, 4, 6, 8) val mapRDD: RDD[Int] = rdd.map( _ * 2 ) mapRDD.collect...
04.Spark RDD创建简介
04.Spark RDD创建简介一、创建RDD1.1 RDD创建方式大概分为四种(1)从集合(内存中创建)RDD从集合中创建 RDD,Spark 主要提供了两个方法:parallelize 和 makeRDDparallelizedef parallelize[T](seq: Seq[T], numSlices: Int = defaultParallelism)(implicit arg0: ClassTag[T]): RDD[T]参数1:Seq集合,必须。参数2:分区数,默认为该Application分配到的资源的CPU核数//默认分区数创建RDD val rdd1 = sparkC...