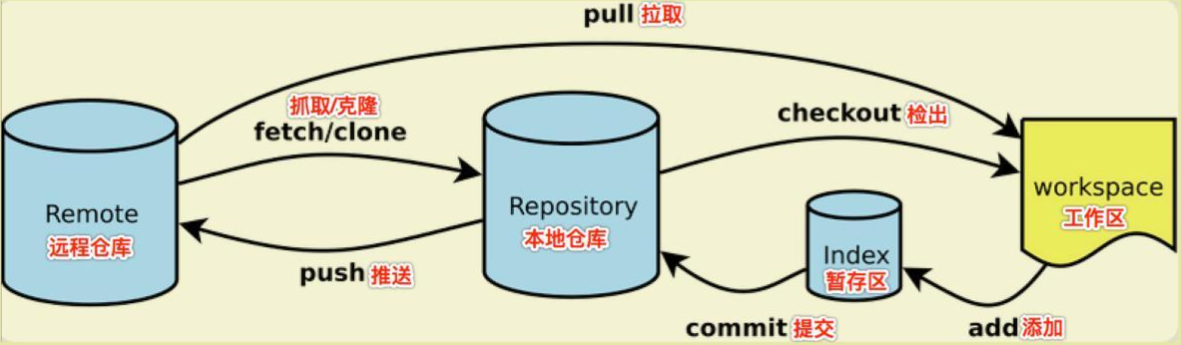
Git概述
Git概述一、Git简介概念Git是一个开源的分布式版本控制系统,可以有效、高速的处理从很小到非常大的项目版本管理。Git 是 Linus Torvalds 为了帮助管理 Linux 内核开发而开发的一个开放源码的版本控制软件。官网地址:https://git-scm.com/特点优点适合分布式开发,强调个体;公共服务器压力和数据量都不会太大;速度快、灵活;任意两个开发者之间可以很容易的解决冲突;离线工作缺点代码保密性差,一旦开发者把整个库克隆下来就可以完全公开所有代码和版本信息;权限控制不友好,如果需要对开发者限制各种权限的建议使用SVN二、Git的工作区域和流程工作区域介绍工作区(w...

四、Stream流List和Map互转
四、Stream流List和Map互转前言本篇介绍Stream流List和Map互转,同时在转换过程中遇到的问题分析。一、Map转List1.1 分析按照默认顺序mapToList.entrySet().stream().map(a -> new User(a.getKey(), a.getValue())).collect(Collectors.toList());根据key排序mapToList.entrySet().stream().sorted(Comparator.comparing(a -> a.getKey())).map(a -> new User(a....

MySQL按照日期统计报表
MySQL按照日期统计报表前言这篇文章主要介绍了mysql按照天统计报表当天没有数据填0的实现方法,需要的朋友可以参考下一、问题复现按照天数统计每天的总数,如果其中有几天没有数据,那么group by 返回会忽略那几天,如何填充0?如下图,统计的10-3~10-10 7天的数据,其中只有8号和10号有数据,这样返回,数据只有2个,不符合报表统计的需求。期望没有值填02.按天分组我们用一组连续的天数作为左表然后left join 要查询的数据 最后group by.:连续天数表 t1 left join 业务数据 t2 group by t1.day ,如下:SELECT t1.`day...
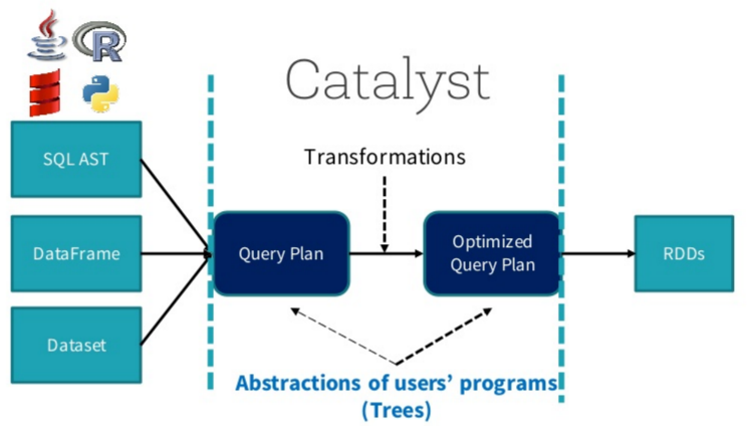
10.【转载】SparkSQL之Join实现介绍
[TOCM]10.【转载】SparkSQL之Join实现介绍前言 在阐述Join实现之前,先简单介绍SparkSQL的总体流程,一般地,我们有两种方式使用SparkSQL, 一种是直接写sql语句,这个需要有元数据库支持,例如Hive等,另一种是通过Dataset/DataFrame编写Spark应用程序。 如下图所示,sql语句被语法解析(SQL AST)成查询计划,或者我们通过Dataset/DataFrame提供的APIs组织成查询计划, 查询计划分为两大类:逻辑计划和物理计划,这个阶段通常叫做逻辑计划,经过语法分析(Analyzer)、 一系列查询优化(Optim...

09.SparkSQL数据的加载和保存
09.SparkSQL数据的加载和保存一、通用的加载和保存方式 SparkSQL 提供了通用的保存数据和数据加载的方式。这里的通用指的是使用相同的 API,根据不同的参数读取和保存不同格式的数据,SparkSQL 默认读取和保存的文件格式 为 parquet1.1 加载数据spark.read.load是加载数据的通用方法下方都是spark.read支持的加载数据方式如果读取不同格式的数据,可以对不同的数据格式进行设定加载数据常用命令scala> spark.read.format("…")[.option("…")].loa...
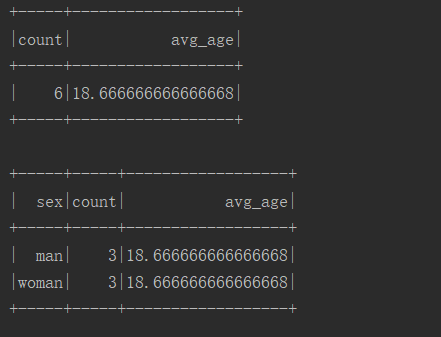
08.UDF和UDAF函数介绍
08.UDF和UDAF函数介绍前言UDF、UDAF、UDTF都是用户自定义函数,用户可以通过 spark.udf 功能添加自定义函数,实现自定义功能。UDF:用户自定义函数(User Defined Function),一行输入一行输出。UDAF:用户自定义聚合函数(User Defined Aggregate Function),多行输入一行输出。UDTF:用户自定义表函数(User Defined Table Generating Function),一行输入多行输出。聚合函数和普通函数的区别:普通函数是接受一行输入产生一个输出,聚合函数是接受一组(一般是多行)输入然后产生一个输出,...
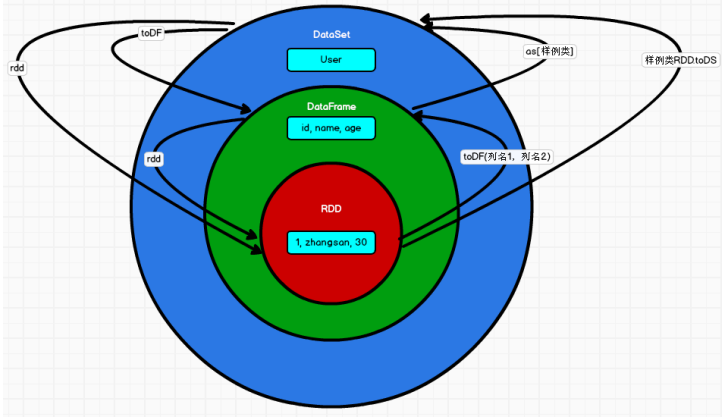
07.RDD、DataFrame和DataSet对比与转换
07.RDD、DataFrame和DataSet对比与转换一、对比1.1 版本产生对比Spark1.0 => RDDSpark1.3 => DataFrameSpark1.6 => Dataset 如果同样的数据都给到这三个数据结构,他们分别计算之后,都会给出相同的结果。不 同是的他们的执行效率和执行方式。在后期的 Spark 版本中,DataSet 有可能会逐步取代 RDD 和 DataFrame 成为唯一的 API 接口。1.2 三者的共性RDD、DataFrame、DataSet 全都是 spark 平台下的分布式弹性数据集,为处理超大型数 据提供...

06.【转载】Dataset (DataFrame) 的基础操作(二)
06.【转载】Dataset (DataFrame) 的基础操作(二)三、Column 对象导读Column 表示了 Dataset 中的一个列, 并且可以持有一个表达式, 这个表达式作用于每一条数据, 对每条数据都生成一个值, 之所以有单独这样的一个章节是因为列的操作属于细节, 但是又比较常见, 会在很多算子中配合出现全套代码展示:package com.spark.transformation import com.spark.Person import org.apache.log4j.{Level, Logger} import org.apache.spark.sql imp...

05.【转载】Dataset (DataFrame) 的基础操作(一)
05.【转载】Dataset (DataFrame) 的基础操作(一)导读这一章节主要目的是介绍 Dataset 的基础操作, 当然, DataFrame 就是 Dataset, 所以这些操作大部分也适用于 DataFrame有类型的转换操作无类型的转换操作基础 Action空值如何处理统计操作一、有类型转换操作1.1 flatMap通过 flatMap 可以将一条数据转为一个数组, 后再展开这个数组放入 Dataset//flatmap val ds1 = Seq("hello spark", "hello hadoop").toDS ds1.f...
04.DataFrame常用API
04.DataFrame常用API一、介绍Spark SQL中的DataFrame类似于一张关系型数据表。在关系型数据库中对单表或进行的查询操作,在DataFrame中都可以通过调用其API接口来实现。可以参考,Scala提供的DataFrame API。二、DataFrame操作2.1 Action操作方法说明collect()返回值是一个数组,返回dataframe集合所有的行collectAsList()返回值是一个Java类型的数组,返回dataframe集合所有的行count()返回一个number类型的,返回dataframe集合的行数describe(cols: Strin...