
Spark Core案例实操(六)
[TOC]一、HanLP介绍HanLP中文分词,面向生产环境的自然语言处理工具包,HandLP是由一系列模型与算法组成的Java工具包,目标是普及自然语言处理在生产环境中的应用。官方网址:http://www.hanlp.com/添加Maven依赖<dependency> <groupId>com.hankcs</groupId> <artifactId>hanlp</artifactId> <version>portable-1.7.7</version> </depend...
Spark Core案例实操(五)
一、准备数据准备agent.log:时间戳,省份,城市,用户,广告,中间字段使用空格分隔。需求描述统计出每一个省份每个广告被点击数量排行的Top3需求分析二、实现2.1 步骤1.获取原始数据 2.将原始数据进行结构的转换,方便统计 3.将转换后的数据进行分组聚合 4.将聚合的结果进行结构中转换 5.将转换结构后的数据根据省份进行分组 6.将分组后的数据组内排序(降序),取前3名 7.采集的数据打印到控制台2.2 代码import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} /** ...

Spark Core案例实操(四)
一、需求页面单跳转换率统计需求说明计算页面单跳转化率,什么是页面单跳转换率,比如一个用户在一次 Session 过程中 访问的页面路径 3,5,7,9,10,21,那么页面 3 跳到页面 5 叫一次单跳,7-9 也叫一次单跳, 那么单跳转化率就是要统计页面点击的概率。比如:计算 3-5 的单跳转化率,先获取符合条件的 Session 对于页面 3 的访问次数(PV) 为 A,然后获取符合条件的 Session 中访问了页面 3 又紧接着访问了页面 5 的次数为 B, 那么 B/A 就是 3-5 的页面单跳转化率。在该模块中,需要根据查询对象中设置的 Session 过滤条件,先将对应得 ...

Spark Core案例实操(三)
一、需求Top10 热门品类中每个品类的 Top10 活跃 Session 统计说明在上个需求的基础上,增加每个品类用户 session 的点击统计二、功能实现2.1 实现步骤1.过滤原始数据,保留点击和前10品类ID 2.根据品类ID和sessionId进行点击量的统计 3.将统计的结果进行结构的转换 (( 品类ID,sessionId ),sum) => ( 品类ID,(sessionId, sum) ) 4.相同的品类进行分组 5.将分组后的数据进行点击量的排序,取前10名2.2 代码import org.apache.spark.rdd.RDD import org.apa...
Spark Core案例实操(二)
前言本篇根据Spark Core案例实操(一)中需求继续对代码进行优化,减少shuffle,提高性能。五、实现方案三在方案一和二中,reduceByKey算子使用过多,因为reduceByKey在进行聚合时也会存在shuffle,影响代码的整体性能。5.1 分析在读取数据之后直接转换成如下结构:点击的场合 : ( 品类ID,( 1, 0, 0 ) ) 下单的场合 : ( 品类ID,( 0, 1, 0 ) ) 支付的场合 : ( 品类ID,( 0, 0, 1 ) )再将相同的品类ID的数据进行分组聚合( 品类ID,( 点击数量, 下单数量, 支付数量 ) )这样可以简化步骤,同时减少许多r...
Spark Core案例实操(一)
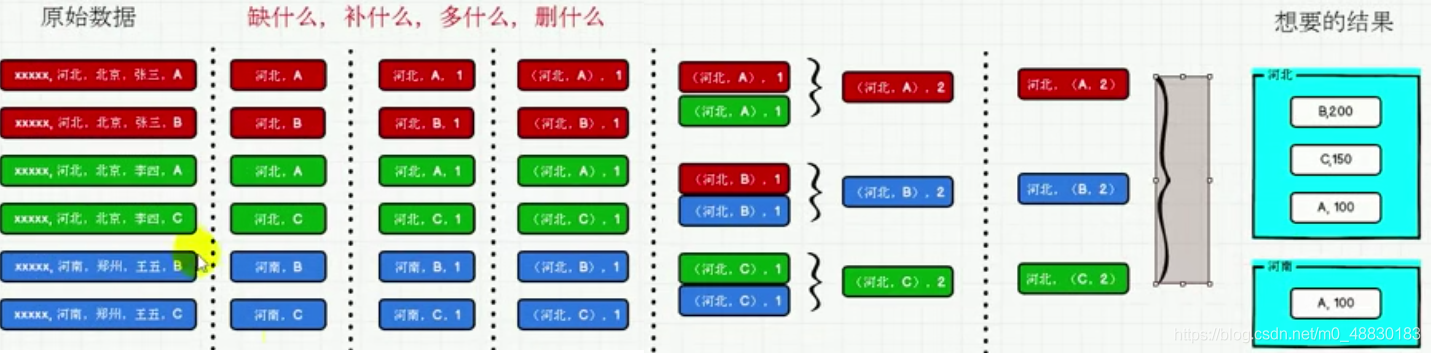
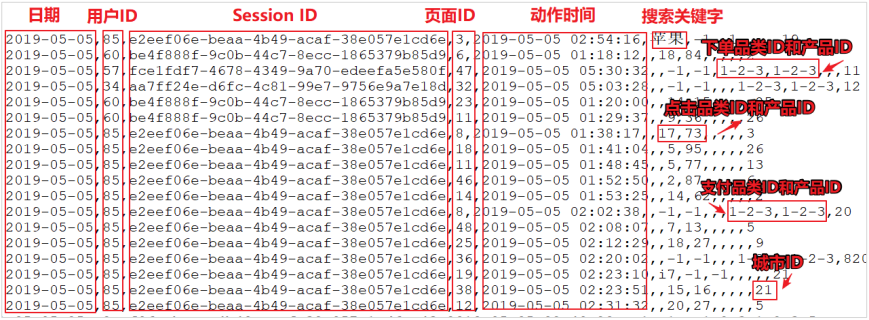
前言本篇将根据电商真实需求,进行案例实操一、数据准备上面的数据图是从数据文件中截取的一部分内容,表示为电商网站的用户行为数据,主要包含用户的 4 种行为:搜索,点击,下单,支付。数据规则如下:数据文件中每行数据采用下划线分隔数据每一行数据表示用户的一次行为,这个行为只能是4 种行为的一种如果搜索关键字为 null,表示数据不是搜索数据如果点击的品类 ID 和产品 ID 为-1,表示数据不是点击数据针对于下单行为,一次可以下单多个商品,所以品类 ID 和产品 ID 可以是多个,id 之 间采用逗号分隔,如果本次不是下单行为,则数据采用 null 表示支付行为和下单行为类似详细字段说明:编号...
07.DStream优雅关闭
[TOC]前言流式任务需要 7*24 小时执行,但是有时涉及到升级代码需要主动停止程序,但是分布式程序,没办法做到一个个进程去杀死,所有配置优雅的关闭就显得至关重要了。一、概念非优雅关闭两种方式:kill -9 processIdyarn -kill applicationId弊端:由于Spark Streaming是基于micro-batch机制工作的,按照间隔时间生成RDD,如果在间隔期间执行了暴力关闭,那么就会导致这段时间的数据丢失,虽然提供了checkpoint机制,可以使程序启动的时候进行恢复,但是当出现程序发生变更的场景,必须要删除掉checkpoint,因此这里就会有丢失的...
06.DStream输出
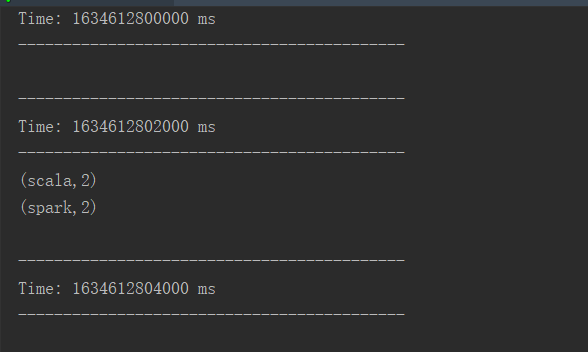
[TOC]一、概念 输出操作允许DStream的操作推到如数据库、文件系统等外部系统中。因为输出操作实际上是允许外部系统消费转换后的数据,它们触发的实际操作是DStream转换。与 RDD 中的惰性求值类似,如果一个 DStream 及其派生出的 DStream 都没有被执行输出操作,那么这些 DStream 就都不会被求值。如果 StreamingContext 中没有设定输出 操作,整个context就都不会启动。二、操作属性属性说明print()在运行流程序的驱动结点上打印 DStream 中每一批次数据的最开始 10 个元素。这用于开发和调试。在 Python A...
05.DStream转换
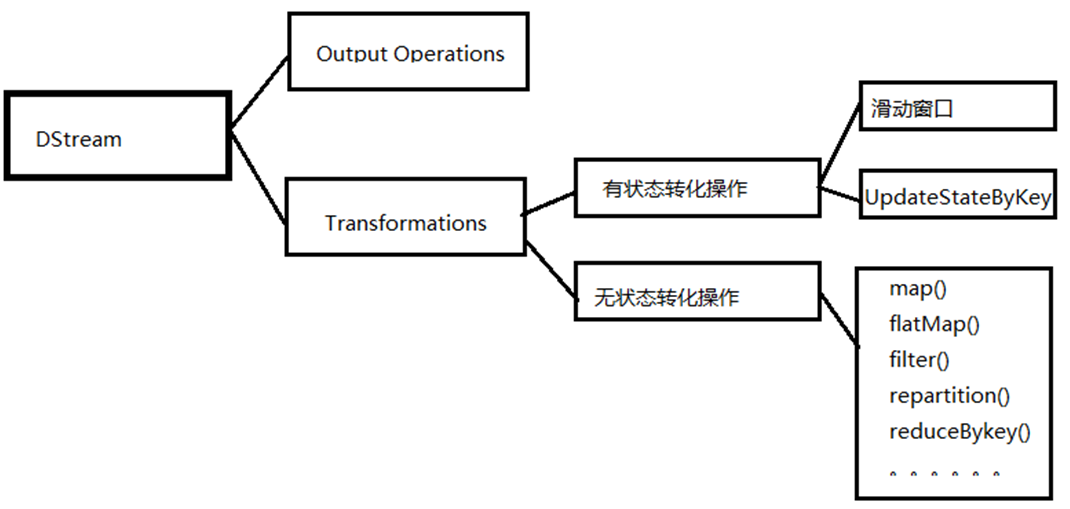
[TOC]一、概念DStream的原语与RDD类似,分分为转换(Transformation)和输出(Output)两种,此外还有一些特殊的原语,如:updateStateByKey,transform以及各种窗口(window)相关的原语。转换分类:DStream转换操作包括无状态转换和有状态转换。无状态转换:每个批次的处理不依赖于之前批次的数据。有状态转换:当前批次的处理需要使用之前批次的数据或者中间结果。有状态转换包括基于滑动窗口的转换和追踪状态变化的转换(updateStateByKey)。二、无状态转换无状态的转化操作,就是把简单的RDD转化操作应用到每个批次上,也就是转化DS...
04.SparkStreaming之Kafka数据源
[TOC]一、概述1.1 概念kafka作为一个实时的分布式消息队列,实时的生产和消费消息,这里我们可以利用SparkStreaming实时计算框架实时地读取kafka中的数据然后进行计算。1.2 创建DStream方式在spark1.3版本后,kafkaUtils里面提供了两个创建dstream的方法:KafkaUtils.createDstream(需要receiver接收)Receiver作为常驻的Task运行在Executor等待数据,但是一个Receiver效率低,需要开启多个,再手动合并数据(union),再进行处理,很麻烦。KafkaUtils.createDirectSt...