李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
Spark Core案例实操(一)
Leefs
2021-10-30 PM
882℃
0条
### 前言 本篇将根据电商真实需求,进行案例实操 ### 一、数据准备 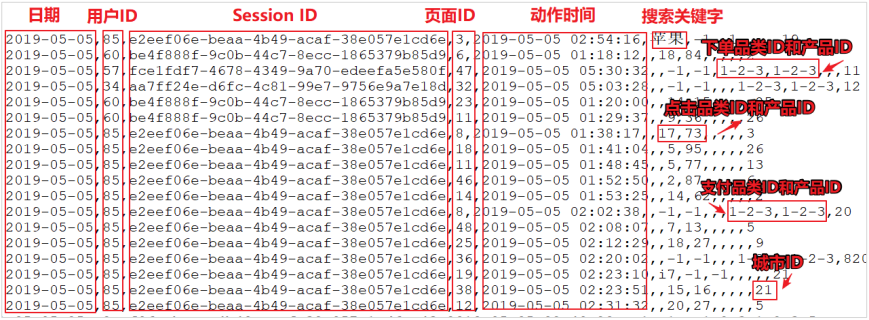 上面的数据图是从数据文件中截取的一部分内容,表示为电商网站的用户行为数据,主要包含用户的 4 种行为:搜索,点击,下单,支付。 **数据规则如下:** + 数据文件中每行数据采用下划线分隔数据 + 每一行数据表示用户的一次行为,这个行为只能是4 种行为的一种 + 如果搜索关键字为 null,表示数据不是搜索数据 + 如果点击的品类 ID 和产品 ID 为-1,表示数据不是点击数据 + 针对于下单行为,一次可以下单多个商品,所以品类 ID 和产品 ID 可以是多个,id 之 间采用逗号分隔,如果本次不是下单行为,则数据采用 null 表示 + 支付行为和下单行为类似 **详细字段说明:** | 编号 | 字段名称 | 字段类型 | 字段含义 | | ---- | ------------------ | -------- | ---------------------------- | | 1 | date | String | 用户点击行为的日期 | | 2 | user_id | Long | 用户的 ID | | 3 | session_id | String | Session 的 ID | | 4 | page_id | Long | 某个页面的 ID | | 5 | action_time | String | 动作的时间点 | | 6 | search_keyword | String | 用户搜索的关键词 | | 7 | click_category_id | Long | 某一个商品品类的 ID | | 8 | click_product_id | Long | 某一个商品的 ID | | 9 | order_category_ids | String | 一次订单中所有品类的 ID 集合 | | 10 | order_product_ids | String | 一次订单中所有商品的 ID 集合 | | 11 | pay_category_ids | String | 一次支付中所有品类的 ID 集合 | | 12 | pay_product_ids | String | 一次支付中所有商品的 ID 集合 | | 13 | city_id | Long | 城市 id | **样例类:** ```scala //用户访问动作表 case class UserVisitAction( date: String,//用户点击行为的日期 user_id: Long,//用户的 ID session_id: String,//Session 的 ID page_id: Long,//某个页面的 ID action_time: String,//动作的时间点 search_keyword: String,//用户搜索的关键词 click_category_id: Long,//某一个商品品类的 ID click_product_id: Long,//某一个商品的 ID order_category_ids: String,//一次订单中所有品类的 ID 集合 order_product_ids: String,//一次订单中所有商品的 ID 集合 pay_category_ids: String,//一次支付中所有品类的 ID 集合 pay_product_ids: String,//一次支付中所有商品的 ID 集合 city_id: Long )//城市 id ``` ### 二、需求案例 > Top10 热门品类 > > 先按照点击数排名,靠前的就排名高;如果点击数相同,再比较下 单数;下单数再相同,就比较支付数。 ### 三、实现方案一 #### 3.1 需求分析 分别统计每个品类点击的次数,下单的次数和支付的次数: **(品类,点击总数)(品类,下单总数)(品类,支付总数)** 然后再根据品类进行聚合排序。 #### 3.2 实现步骤 ``` 1.读取原始日志数据 2.统计品类的点击数量:(品类ID,点击数量) 3.统计品类的下单数量:(品类ID,下单数量) 4.统计品类的支付数量:(品类ID,支付数量) 5.将品类进行排序,并且取前10名 6.将结果采集到控台打印出来 ``` #### 3.3 代码 ```scala import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} /** * @author lilinchao * @date 2021/10/30 * @description Top10热门品类 **/ object HotCategoryTop10Analysis01 { def main(args: Array[String]): Unit = { val sparConf = new SparkConf().setMaster("local[*]").setAppName("HotCategoryTop10Analysis") val sc = new SparkContext(sparConf) //1. 读取原始日志数据 //通过外部存储创建RDD val actionRDD = sc.textFile("datas/user_visit_action.txt") //2. 统计品类的点击数量:(品类ID,点击数量) //filter:将数据根据指定的规则进行筛选过滤,符合规则的数据保留,不符合规则的数据丢弃(返回True的保留,False丢弃) val clickActionRDD = actionRDD.filter( action => { //通过【-】分割,第七列为品类ID,如果不为-1,代表被点击 val datas = action.split("_") datas(6) != "-1" } ) //map:一对一地映射 //reduceByKey:相同的key的数据进行value的聚合操作(两两聚合) val clickCountRDD : RDD[(String,Int)] = clickActionRDD.map( action => { val datas = action.split("_") (datas(6),1) } ).reduceByKey(_ + _) // clickCountRDD.foreach(println) //3. 统计品类的下单数量:(品类ID,下单数量) val orderActionRDD = actionRDD.filter( action => { val datas = action.split("_") datas(8) != "null" } ) //orderId => 1,2,3 // 【(1,1),(2,1),(3,1)】 //flatMap:将RDD中的每一个元素进行一对多转换,然后扁平化 val orderCountRDD = orderActionRDD.flatMap( action => { val datas = action.split("_") val cid = datas(8) val cids = cid.split(",") cids.map(id => (id,1)) } ).reduceByKey(_ + _) //4. 统计品类的支付数量:(品类ID,支付数量) val payActionRDD = actionRDD.filter( action => { val datas = action.split("_") datas(10) != "null" } ) // orderid => 1,2,3 // 【(1,1),(2,1),(3,1)】 val payCountRDD = payActionRDD.flatMap( action => { val datas = action.split("_") val cid = datas(10) val cids = cid.split(",") cids.map(id =>(id,1)) } ).reduceByKey(_+_) //5. 将品类进行排序,并且取前10名 // 点击数量排序,下单数量排序,支付数量排序 // 元祖排序:先比较第一个,再比较第二个,再比较第三个,依次类推 // ( 品类ID, ( 点击数量, 下单数量, 支付数量 ) ) //cogroup = connect + group //cogroup:对两个RDD中的KV元素,每个RDD中相同key中的元素分别聚合成一个集合。 //与reduceByKey不同的是针对两个RDD中相同的key的元素进行合并。 //cogroup有可能会存在shuffle val cogroupRDD: RDD[(String, (Iterable[Int], Iterable[Int], Iterable[Int]))] = clickCountRDD.cogroup(orderCountRDD, payCountRDD) // cogroupRDD.foreach(println) //mapValues:针对KV类型的映射map,当K不变,只对V进行映射时,可采用mapValues简化 //从迭代器中取出三个元素 val analysisRDD = cogroupRDD.mapValues{ case (clickIter,orderIter,payIter) => { var clickCnt = 0 //迭代器有两个操作,next 和hasNext。 // next返回迭代器的下一个元素,hasNext用于检查是否还有下一个元素。 val iter1 = clickIter.iterator if(iter1.hasNext){ clickCnt = iter1.next() } var orderCnt = 0 val iter2 = orderIter.iterator if(iter2.hasNext){ orderCnt = iter2.next() } var payCnt = 0 val iter3 = payIter.iterator if(iter3.hasNext){ payCnt = iter3.next() } (clickCnt,orderCnt,payCnt) } } // analysisRDD.foreach(println) //该操作用于排序数据。在排序之前,可以将数据通过 f 函数进行处理,之后按照 f 函数处理的结果进行排序,默认为升序排列,第二个参数为False为降序。 val resultRDD = analysisRDD.sortBy(_._2,false).take(10) //6. 将结果采集到控台打印出来 resultRDD.foreach(println) sc.stop() } } ``` **运行结果** ``` (15,(6120,1672,1259)) (2,(6119,1767,1196)) (20,(6098,1776,1244)) (12,(6095,1740,1218)) (11,(6093,1781,1202)) (17,(6079,1752,1231)) (7,(6074,1796,1252)) (9,(6045,1736,1230)) (19,(6044,1722,1158)) (13,(6036,1781,1161)) ``` **代码分析** 通过代码我们不难看出两个问题: + actionRDD重复使用 + cogroup有可能会存在shuffle,性能可能较低 对此我们可以对代码做进一步优化。 ### 四、实现方案二 在实现方案一中cogroup性能可能较低,在进行步骤五时,我们可以换一种方案进行实现。 #### 4.1 分析 **可以通过模式匹配做如下转换操作:** ``` (品类ID, 点击数量) => (品类ID, (点击数量, 0, 0)) (品类ID, 下单数量) => (品类ID, (0, 下单数量, 0)) (品类ID, 支付数量) => (品类ID, (0, 0, 支付数量)) ``` **再将三个数据源合并在一起,统一进行聚合计算:** + 先将点击数量和下单数量进行合并 ``` (品类ID, (点击数量, 0, 0)) (品类ID, (0, 下单数量, 0)) ==> (品类ID, (点击数量, 下单数量, 0)) ``` + 再将合并后的结果与支付数量进行合并,得到最终结果 ``` (品类ID, (点击数量, 下单数量, 0)) (品类ID, (0, 0, 支付数量)) ==> ( 品类ID, ( 点击数量, 下单数量, 支付数量 ) ) ``` #### 4.2 代码实现 ```scala import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} /** * @author lilinchao * @date 2021/10/30 * @description Top10热门品类 **/ object HotCategoryTop10Analysis02 { def main(args: Array[String]): Unit = { val sparConf = new SparkConf().setMaster("local[*]").setAppName("HotCategoryTop10Analysis") val sc = new SparkContext(sparConf) //1. 读取原始日志数据 val actionRDD = sc.textFile("datas/user_visit_action.txt") actionRDD.cache() //2. 统计品类的点击数量:(品类ID,点击数量) val clickActionRDD = actionRDD.filter( action => { val datas = action.split("_") datas(6) != "-1" } ) val clickCountRDD : RDD[(String,Int)] = clickActionRDD.map( action => { val datas = action.split("_") (datas(6),1) } ).reduceByKey(_ + _) //3. 统计品类的下单数量:(品类ID,下单数量) val orderActionRDD = actionRDD.filter( action => { val datas = action.split("_") datas(8) != "null" } ) //orderId => 1,2,3 // 【(1,1),(2,1),(3,1)】 val orderCountRDD = orderActionRDD.flatMap( action => { val datas = action.split("_") val cid = datas(8) val cids = cid.split(",") cids.map(id => (id,1)) } ).reduceByKey(_ + _) //4. 统计品类的支付数量:(品类ID,支付数量) val payActionRDD = actionRDD.filter( action => { val datas = action.split("_") datas(10) != "null" } ) // orderid => 1,2,3 // 【(1,1),(2,1),(3,1)】 val payCountRDD = payActionRDD.flatMap( action => { val datas = action.split("_") val cid = datas(10) val cids = cid.split(",") cids.map(id =>(id,1)) } ).reduceByKey(_+_) //5. 将品类进行排序,并且取前10名 // 点击数量排序,下单数量排序,支付数量排序 // 元祖排序:先比较第一个,再比较第二个,再比较第三个,依次类推 // ( 品类ID, ( 点击数量, 下单数量, 支付数量 ) ) //当map转换复杂的数据类型时,通过【模式匹配】简洁表达 val rdd1 = clickCountRDD.map{ case (cid,cnt) => { (cid,(cnt,0,0)) } } val rdd2 = orderCountRDD.map{ case (cid,cnt) => { (cid,(0,cnt,0)) } } val rdd3 = payCountRDD.map{ case (cid,cnt) => { (cid,(0,0,cnt)) } } // 将三个数据源合并在一起,统一进行聚合计算 //union:并集 val soruceRDD: RDD[(String, (Int, Int, Int))] = rdd1.union(rdd2).union(rdd3) // soruceRDD.foreach(println) val analysisRDD = soruceRDD.reduceByKey( (t1,t2) => { (t1._1+t2._1, t1._2 + t2._2, t1._3 + t2._3) } ) val resultRDD = analysisRDD.sortBy(_._2,false).take(10) //6. 将结果采集到控台打印出来 resultRDD.foreach(println) sc.stop() } } ``` **运行结果** ``` (15,(6120,1672,1259)) (2,(6119,1767,1196)) (20,(6098,1776,1244)) (12,(6095,1740,1218)) (11,(6093,1781,1202)) (17,(6079,1752,1231)) (7,(6074,1796,1252)) (9,(6045,1736,1230)) (19,(6044,1722,1158)) (13,(6036,1781,1161)) ``` ### 结尾 因为本篇使用的示例数据`user_visit_action.txt`文件由于数据量较大将不在下方贴出。 直接在微信公众号【Java和大数据进阶】回复:**sparkdata**,即可获取。
标签:
Spark
,
Spark Core
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://lilinchao.com/archives/1595.html
上一篇
07.DStream优雅关闭
下一篇
Spark Core案例实操(二)
取消回复
评论啦~
提交评论
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
标签云
ClickHouse
栈
Docker
Eclipse
数据结构和算法
持有对象
Hadoop
Yarn
机器学习
队列
Flume
Zookeeper
JavaWeb
排序
GET和POST
FileBeat
CentOS
线程池
Golang基础
Jenkins
Typora
DataX
BurpSuite
JavaSE
散列
SpringBoot
人工智能
Spark Streaming
JVM
Spark Core
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞